因果图的思想优化长尾问题
论文链接: https://arxiv.org/abs/2009.12991
代码链接: https://github.com/KaihuaTang/Long-Tailed-Recognition.pytorch
这篇文章和之前有介绍过的一篇场景图生成的文章Unbiased Scene Graph Generation from Biased Training思想比较类似, 作者也是同一个团队。贴一个传送门,方便感兴趣的同学浏览。
之所以说思想类似,是因为这两篇文章不仅都用来解决长尾问题,而且都用到了因果图的的思想。在看这篇论文的时候,有些内容读起来还是很难理解的,查阅了一些统计学和因果关系的相关概念才觉得清晰了些。这些理论也非常有意思,看完后我觉得在阅读这篇文章前还是很有必要学习的。在写这篇blog的时候,我也尽量把需要用到的背景知识整理出来,方便理解。
背景知识
因果关系
关于因果关系,在https://zhuanlan.zhihu.com/p/111306353中有详细的背景知识。为了方便阅读和加深自己的理解。我在这里精简的引用下,更详细的内容可以去阅读大佬的知乎文章。
《The Book of Why》中将因果理论的探索类比成一个向上的阶梯,包含三个层级:Seeing,Doing和Imaging。
第一层级: Association 关联,对应的是大多数机器学习算法和动物。该层级强调基于被动的观察(passive observation)来预测,通过观察来寻找规律,并非真正的因果。其本质就是条件概率P(Y|X),在观察到X的条件下Y发生的概率,也是传统机器学习里被广泛应用的。
第二层级:Intervention干预, 干预指的是消除因果关系中的混杂影响,推导出真正的因果关系,如随机对照试验。
第三层级:Counterfactual 反事实,counterfactual和干预intervention区分的关键在于“hindsight”(事后来看),即反事实强调在对结果已知观测的基础上再对反事实的问题进行解答。因果推断中的变量
因果推断中有一些专业术语用来表示在因果中不同变量的角色,主要分为混淆变量(confounder),中介变项(mediator),对撞因子(collider)
混淆变量比较通俗的例子是老年人因为退休了会更有时间晨炼,但老年人却比年轻人更容易得癌症,如果不控制年龄的分布,就会得到晨炼的人容易得癌症。这里的年龄就是混淆变量,需要被控制
中介效应指的是从一个变量到另一个变量,中间会有些其他的变量带来影响。比如吃药能带来疾病的好转,可能是药本身起了作用,也可能是心理安慰。比较极端的例子是是不是就会出现用面粉做假药的新闻,对于患者而言,药本身可能没起到作用,但可能由于吃了“药”,觉得自己马上会好,比较积极的心态带来了身体的好转。
对撞因子指的是同时被两个以上变量影响的因素,而这些影响对撞因子的变量之间不见得有因果关系。例如在NBA球员中,会发现身高比较高的人得分率并没有很高,这是因为身高矮的人能进NBA必然是用其他优势弥补了劣势。身高和得分率之间并没有明显的因果关系,而他们都决定能不能进NBA。仔细思考就会发现对撞因子的例子很容易造成幸存者偏差。Propensity Score
倾向评分匹配(Propensity Score Matching) 是一种统计学的方法,指的是在观察研究中,由于种种原因,数据偏差(bias) 和 混杂变量(confounding variable) 较多,倾向评分匹配的方法正是为了减少这些偏差和混杂变量的影响,以便对实验组和对照组进行更合理的比较。
为了能较好说明这个方法的价值,可以用理科里学的随机对照实验(Randomized Controlled Trial data)做对比。随机对照试验在样本量足够的情况下是很科学的评判变量对结果影响的实验方法,但很多时候是不符合科研伦理的,比如要研究吸烟是否有害健康,如果招收大量人员,然后随机分配到吸烟组和不吸烟组,这种实验设计不太容易实现,而且也存在危害测试人员健康的可能。而这个研究课题其实很容易通过观察的研究数据进行实验,面对观察的研究数据,如果不加调整,很容易获得错误的结论,比如拿吸烟组健康状况最好的一些人和不吸烟组健康状况最不好的一些人作对比,得出吸烟对于健康并无负面影响的结论。从统计学角度分析原因,这是因为观察研究并未采用随机分组的方法,无法基于大数定理的作用,在实验组和对照组之间削弱混杂变量的影响,很容易产生系统性的偏差。倾向评分匹配就是用来解决这个问题,消除组别之间的干扰因素。相关工作
Re-Balanced Training: re-blance的方法主要有两种,分别是re-sampling和re-weighting。
Hard Example Mining: 不关注于每个类别样本数量的先验分布,而是关注于难样本用于缓解长尾问题,代表方法是focal loss
Transfer Learning/Two-Stage Approach: 作者总结的这类工作的特点是将头部类的knowledge转移到尾部类,用以改善长尾问题。其中比较有代表性的是Decoupling算法,和受Decoupling启发的BBN算法。BBN在之前的关于长尾问题的文章中也有过总结。
Causal Inference: 因果图推理作者主要列举了一些这方面的著作,当然也提到了自己在场景图生成中的文章方法
作者将视角聚焦于梯度优化器中常用的track——Momentum。在讲解作者是怎么做的之前,让我们回顾下Momentum。Momentum的思想是累积一个历史的梯度信息用来加速优化器,好处主要有以下两点:
- 每次梯度更新的时候,不仅考虑了当前梯度的方向,同时也考虑了之前更新的方向,在梯度优化时,不会抖动的那么随意
- Momentum相当于给梯度优化的方向施加了一个惯性,参数优化时容易突破局部最优解,更可能找到全局最优解.
上面是一些比较定性的分析,关于Momentum为什么能work?https://distill.pub/2017/momentum/做了非常好的可视化,可以直观的感受到Momentum为梯度优化带来的改变
下面的两张图分别是没有Momentum和使用合理参数设置Momentum对模型优化带来的差异,可以看到Momentum能提高网络训练的稳定性,并且同样的迭代次数更容易收敛到全局最优。

回归正题,对于长尾分布的数据集,正是由于Momentum会受之前梯度信息的影响,Momentum所产生的惯性,会带来马太效应,即模型的优化方向会倾向于让模型对头部类的效果更好。
作者将Momentum对网络的作用用因果图抽象了出来,如figure 1(a)所示
上图中,X代表backbone提取到的特征,M代表优化器中的动量,Y代表预测结果,D代表动量所产生的惯性,由于是长尾数据集,这里的D特指对头部类优化的惯性,而在balanced的数据集中,D对每个类别的贡献是一样的。图中的箭头表示彼此的影响,例如,X->Y以为着,Y的得出收到X的影响。从因果图中的关系可以看出节点M和节点D分别代表混淆变量(confounder)和中介效应(mediator)。
M->X代表的是特征图X的是在动量M的影响下训练的,figure 1(b)中可视化了动量M对不同类别的影响,可以发现头部类在动量中占比较大。
知道了混淆变量和中介效应之后,需要做的就是消除这些变量对模型带来的偏见。和Unbiased Scene Graph Generation from Biased Training中类似,接下来需要构建TDE(Total Direct Effect)用于消除偏见,公式如下:
和公式对应的因果图如Figure 3
在计算TDE时需要抹除掉混淆变量M对X的影响,但没有办法得到M的分布。在Causal inference in statistics: A primer的书中有提到Inverse Probability Weighting的公式,这个公式给出了一种思路,即没有办法得到M的分布时,可以看M和X有没有一一对应关系。在这个方法里,M和X确实是有对应关系的。所以可以将对X的采样看成是对M的近似
这里将weights和features的通道/维度划分成k组,可以认为是做了k倍的细粒度采样。这样的好处是通过multi-head多重采样能更好的近似。
M能够做近似之后,还需要考虑 倾向评分(Propensity Score) 的影响,在这个问题中需要对所有类别做归一化的统一分布,也就是考虑每个类别的模长。下面就是得到的Propensity Score的公式, 其中第一项是类别感知的, 其中第一项是class-specific,第二项是class-agnostic。需要第二项的原因是因为从Figure 1(b)中可以看出x也具有bias。
则公式2中的第一项$P (Y = i|do(X = x))$可以表示为
公式2中的第二项和第一项的区别在于使用了空数据$x_0$替代x。而其他项保持不变,这一部分是构建反事实的因果图,相当于让网络仅通过M和D得到Y,而x没起到作用。可以把这部分看作是偏差。
最终的TDE如下式:
结论
和其他方法的对比如下:
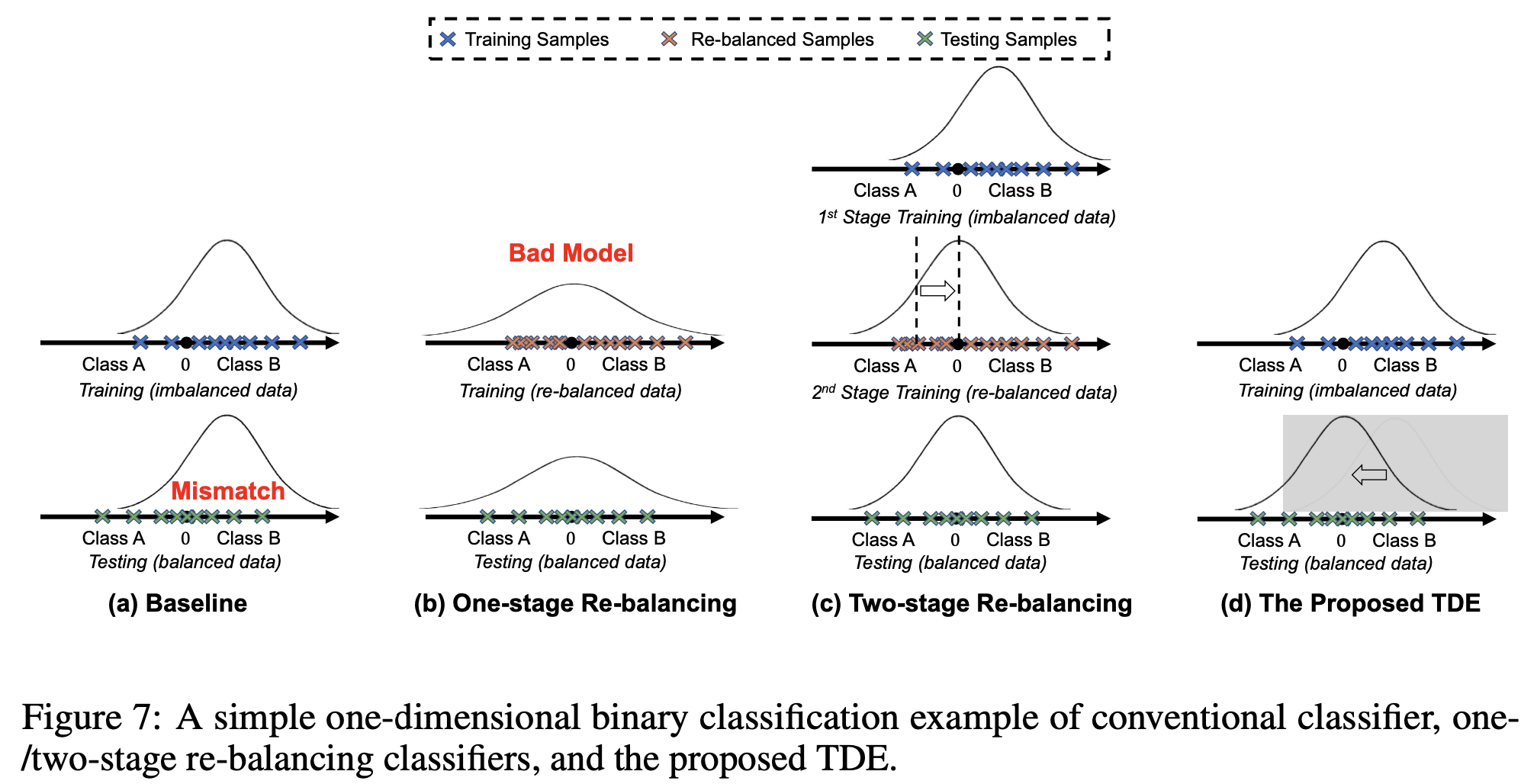
关于本文方法和其他方法的差异,可以用下图表示。
- 在baseline的数据集上有问题是由于训练数据是长尾的,而测试数据是balanced的,存在分布不匹配。
- One-stage Re-balancing的方法本质是改变了训练数据的分布,这种方式会带来错误的模型建模;
- Two-stage Re-balancing的方法是第一阶段先通过原始的数据对模型建模,第二阶段再优化分类器,对分类器边界做调整,所以能work
- 而本文的方法是在测试的时候将分布做了移动
![]()
优势: - 不需要复杂的stage训练方式
- 可适用于多个任务,如图片分类,检测之类
- 不需要依赖数据的分布, 感觉这个优势对于online的训练比较有意义, 因为其他的训练方式其实都可以获取到数据的数据分布。
笔者总结
要使用作者提供的 https://github.com/KaihuaTang/Long-Tailed-Recognition.pytorch 代码中的CausalNormClassifier总结起来有几个要点, 为方便理解,下面要点中的超链接会索引到具体的代码: - 训练的时候需要用multi-head normalized classifier
- 训练时需要记录移动的平均特征
- 测试的时候需要用counterfactual TDE inference,即去除具有头部类倾向的部分
让我们回顾上面的图7,在作者博客的评论部分,有非常简洁的总结, 在这里引用下:- decouple两阶段都是在train过程中,一阶段长尾分布下训练representation + classifier;二阶段直接通过暴力resample来调整classifier。
- de-confound也可以看做两阶段,一阶段在train过程中,通过重采样和normalized的措施来训练representation + classifier;二阶段放在了test过程中,用一阶段中统计的bias来缓解测试中的class bias,得到TDE。
这两篇文章都很巧妙的使用了因果图。虽然很多trick可解释性确实不太强,不过细细思考起来,一些算法流程对整体算法的影响还是比较make sence。私以为在如果算法框架中有些trick能带来收益的同时,也会让带来一些问题负面的影响,就很适合用因果图的思想消除负面影响,不过这确实很考验对于问题的抽象能力和对因果图的理解欢迎关注我的公众号!
![enter description here]()
