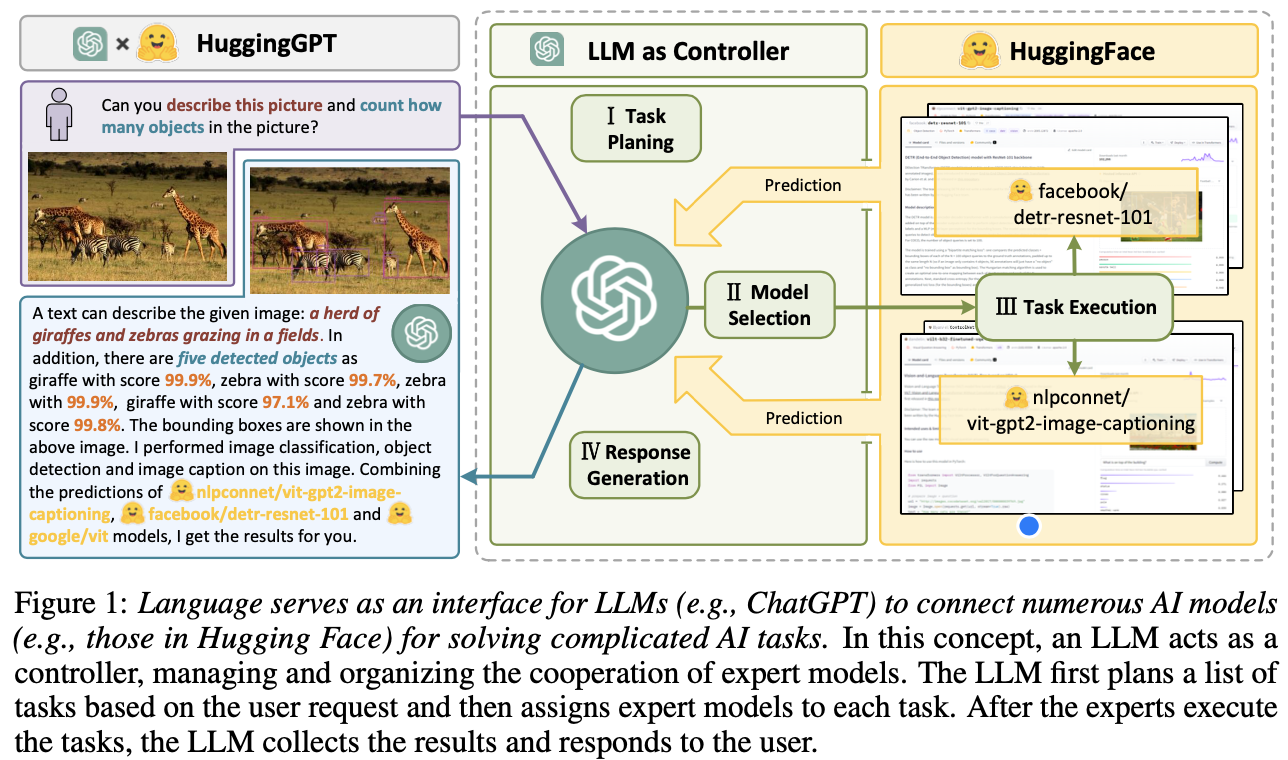
HuggingGPT——GPT与HuggingFace的火花
论文链接: https://arxiv.org/abs/2303.17580
代码链接: https://github.com/microsoft/JARVIS
上一篇介绍过Visual Programming, HiggingGPT的思想和其非常类似,也是用大语言模型做任务的拆解,再调用HuggingFace上的模型完成任务。
因为太相似了,因此这篇文章主要介绍下HuggingGPT的实现方式,相对篇幅会短点,如果你对这类的文章感兴趣,可以看梳理的更详细的Visual Programming。
HuggingGPT论文中的提供的例子还是很惊艳的,面对更加问题更加复杂的问题都能解决。而且HuggingGPT不光局限于视觉这一个模态,而是将任务划分为了NLP、CV、audio、video四种场景,每个场景都可以调用HuggingFace上的模型解决
HuggingGPT完成一个任务可以分为以下几步:
- 任务规划: 使用ChatGPT分析请求,将请求拆解成一系列下游任务
- 模型选择: 根据拆解出的任务,和HuggingFace上模型的描述,选择合适的模型
- 任务执行: 根据拆解的任务和选择的模型,调用模型并将结果返回和ChatGPT
- 生成答案: ChatGPT汇总各个模型的结果,返回最终的答案
模块
任务规划
有两种方式,分别是Specification-based Instruction和Demonstration-based Parsing
Specification-based Instruction: 提供规范的模版,期望LLM可以遵循一些特殊的规范(例如JSON)解析任务, 格式为[{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]
- task: 任务的类型,可以选择的类型如下:

- id: 对任务唯一的标识
- dep: 依赖
- augs: 参数

Demonstration-based Parsing: 为了让GPT更好的理解任务规划的意图,可以在prompt中提供一些演示。例如希望做什么样的任务,这个任务期望的任务规划结果

模型选择
完成任务规划后,需要选择最优的模型。HuggingGPT使用的是Hugging Face上的模型描述。让GPT选择最贴近任务,且效果最好的模型。因为文本长度的限制,不能把所有模型描述都作为prompt,需要根据先任务类型做筛选,再根据下载量排序,选择top-K的模型id和描述作为候选.
输入的prompt是提供一个模型列表,要求从中选择出最好的模型。输出是模型的id及选择的原因{"id": "id", "reason": "your detail reason for the choice"}

任务执行
完成前两步后,这一步就是具体的模型执行。其中一个挑战是不同任务之间可能会存在依赖关系,解决方法是使用特殊的符号<resource>,代表着依赖关系,例如<resource>-task_id代表依赖task_id的任务。HuggingGPT在执行的时候会将该符号替换为先决任务。在执行的过程中,能保证先执行前置任务.
生成答案
Hugging GPT汇总之前三个步骤的信息,生成最终的答案.Prompt中也要求,直截了当的回答问题,并以第一人称的视角展示分析和模型的推理结果,如果包含输出文件的路径,需要补充出来,且如果回答不了问题,也需要告知

实验
定性结果

任务: 生成一张女孩在读书的图像,且女孩的姿势和示例中的男孩相同,用你的声音描述生成的新图像
任务规划:
- 1: 检测姿态
- 2: 根据姿态和文本”a reading girl”生成图像, 依赖任务1
- 3: 图像分类,作为描述图片的一部分信息, 依赖任务2
- 4: 目标检测, 获取物体框的类别和坐标,依赖任务2
- 5: 图生文, 作为描述图片的一部分信息, 依赖任务2
- 6: 文生音, 结合所有信息,及完成任务的过程总结输出,并转为音频, 依赖任务5
模型选择:按task类型在Hugging Face选择模型
任务执行&回答问题
定性评估
因为任务规划是整个方法的第一个模块,也决定了整个pipeline的效果,因此也可以看作是最重要的模块。主要分为三种类型:
- Single Task: 问题的执行步骤只能拆分成一个任务,当标注的任务名称和预测的完全一致时,认为是正确。 评测精度/召回/F1
- Sequential Task: 问题的执行步骤能被拆分成一系列顺序执行的任务。评测精度/召回/F1的编辑距离
- Graph Task: 问题的执行步骤能被拆分成有向无环图组成的任务,因为图中有多种拓扑结构,仅使用F1不能反映LLM任务规划的能力,因为使用的是效果更好的LLM模型——GPT4评估所使用的LLM模型任务规划的好坏。
数据集
使用GPT-4生成规划任务的伪标签,也邀请一些专家标注了一些复杂的请求。对比了Alpaca-7b、Vicuna-7b和GPT3.5三个模型的好坏
下面对比的是用GPT-4生成伪标签的数据集上,三个模型的评测效果。GPT3.5在基本所有任务上都优于另外两个模型。


下面对比的是在人工生成的模型上,Alpaca-7b、Vicuna-7b、GPT3.5和GPT-4模型的效果对比, 前三个模型的表现和用GPT-4生成伪标签的相似,并且GPT-4的效果大幅领先。

存在的一些问题
- 严重依赖LLM的能力,因此提高LLM任务规划的能力非常重要
- 整个系统的效率不高,整个系统高度依赖LLM,在解决一个较复杂问题的流程中会多次调用LLM,影响耗时。
- Token长度的限制,在HuggingGPT中使用了一些规则让LLM对于判断的模型描述大大减少。但仍然存在可能超出长度限制的问题,因此总结模型描述也是一个问题。(LLM也具有总结一段文本的能力,应该也可以用LLM先总结描述,再执行判断)
- 整个系统效果不太稳定,因此LLM的输出结果是不可控的
总结
HuggingGPT在该方法不足的部分提到了关于效率的问题,依赖LLM模型确实会带来耗时的增加。人类在思考的时候也会有类似的问题,《思考的快与慢》的序中有这样一则点评描写两种思维系统在所花时间上的差异。
生活就像点菜,饥饿时菜会点得特别多,但吃一阵就会意识到浪费;如果慢条斯理地盘算怎么点菜,别人已经要吃完了。这就是决策的复杂性。
有的场景更适合系统一,而有的场景更适合系统二。这两种解决问题的方式都很有价值, 而且这两篇文章类似系统二的思考方式可能是现有条件下实现通用智能最好的方式