NER&RE联合抽取汇总
背景:
- NER任务: 预测文本中具有特定意义的实体,如人名,地名等
- RE任务: 多分类任务,通过NER得到了实体之后,预测任意两个实体存在怎样的关系
实体关系抽取可以分为两类方法:
- pipeline models:可以任意组合不同的模型和数据,但关系模型使用实体模型的的预测结果作为其输入,会导致实体预测的错误传播到关系预测模型中
- joint models:在一个模型中同时完成实体和关系抽取的任务,增强实体和关系的信息交互
关系抽取需要考虑的问题: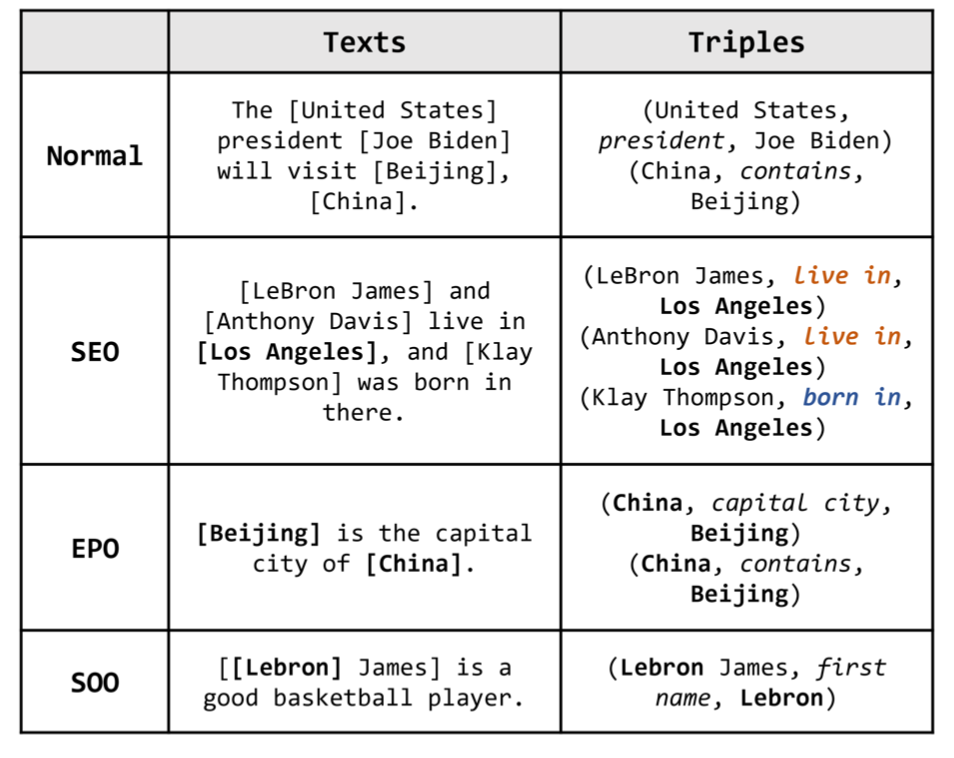
- SEO: (Single Entity Overlap),一个实体与多个其他实体有关系
- EPO(Entity Pair Overlap): 两个实体之间有多个关系
- SOO(Subject Object Overlap)/HTO)(Head Tail Overlap): subject和object存在嵌套的情形
CsRel:A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
论文: https://arxiv.org/pdf/1909.03227.pdf
代码: https://github.com/weizhepei/CasRel
CasRel:
- 对关系三元组联合建模
- 通过下面的公式,可以将句子中含有(s,r,o)三元组的最大似然估计转换为先提取s后,在关系r的前提下,提取对应的o
![enter description here]()


Cascade: 先抽取subject, 再抽取对应的关系和object。整个网络分成两步:
- 先抽取subject,再抽取对应的关系和object
- 对于每一个关系,都要做对应关系的object抽取,如果有N个关系,则有2N个序列
subject tagger
采用两个单独的二分类器分别检测subject实体的开始和结束,具体做法是经过bert后输出两个序列,start序列将实体的头token标记为1,end序列将实体的尾token标记为1。如果一个句子中检测出多个实体,则采用nearest的原则解码

relation-specific object taggers
将subject的信息作为先验信息,带入到object和关系的抽取中。由于每个span的宽度不同,为了保证x和v的维度一致,需要将subject做max pooling

TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
论文: https://arxiv.org/pdf/2010.13415.pdf
代码: https://github.com/131250208/TPlinker-joint-extraction
之前工作存在的问题
- 曝光偏差(exposure bias): 在训练时,grouth truth token作为上下文,训练object和关系。而在预测时,用预测的subject作为输入,导致了训练和测试时的偏差
- 误差传播: 错误不可逆有的传播,如果subject未抽取到,则object和关系也将预测不出来

TPLinker通过三种类型的span矩阵抽取实体关系三元组,N是序列长度,R是关系的总数
- EH-to-ET: 表示实体的头尾关系,1个N*N的矩阵。如两个实体:New York City:M(New, City) =1; De Blasio:M(De, Blasio) =1,在上图中紫色标记。
- SH-to-OH: 表示subject和object的头部token间的关系,是R个N*N矩阵;如三元组(New York City, mayor,De Blasio):M(New, De)=1,在上图中位红色标记。
- ST-to-OT: 表示subject和object的尾部token间的关系,是R个N*N的矩阵;如三元组(New York City, mayor,De Blasio):M(City, Blasio)=1,在上图中为蓝色标记。
共有2R+1个矩阵,为了防止稀疏计算,下三角矩阵不参与计算。实体标注不会产生下三角矩阵,但关系可能会存在,若关系矩阵存在于下三角,则将其转置到上三角,并由标记1转换为标记2
解码过程

- 解码EH-to-ET可以得到句子中所有的实体,用实体头token idx作为key,实体作为value,存入字典D中;得到三个实体{New York,New York City,De Blasio};则D={New:(New York,New York City),De:(De Blasio)}
- 对每种关系r,解码SH-to-OH得到token对并在D中关联其token idx的实体value;以关系mayor为例,解码SH-to-OH得到(De,New),关联到D可以知道subject实体为(De Blasio), object实体为(New York, New York City)
- 解码ST-to-OT得到E=(City,Blasio), 关联上面的到的subject和object集合可以确认subject为(De Blasio),object为New York City
PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction
论文: https://arxiv.org/pdf/2106.09895.pdf
代码: https://github.com/hy-struggle/PRGC
CsRel缺点:
- 每个subject需要判断大量冗余的关系
- 每次只能处理一个subject,工程效率不太友好
TPLinker缺点:
- 构建了大量的关系矩阵,导致标签稀疏和收敛速度慢
- 同样存在关系冗余
将实体和关系抽取建模成三个子任务:
- 关系判断(Relation Judgement): 输入为句子的特征向量h, 输出是长度为r的向量。判断句子中可能存在的关系。
- 实体提取(Entity Extraction): 输入是句子的特征向量h和可能存在的关系$R_{pot}$。 对于每个候选关系,采用softmax进行两次三分类,第一次确定头实体的BIO标签,第二次确定尾实体的BIO标签。在抽取subject和object时,用到了关系的特征。将关系向量加到对应token向量上,经过全连接层、softmax得到分类概率。

- 主宾语对齐(Subject-object Alignment):输入是句子的特征向量。构建二维矩阵$M\in R^{n*n}M_{i,j}$存储的是subject实体首词为第i个token,object实体首词为第j个token的概率。由于通过实体提取获取了句子中在每个关系$r_{i}$相应的实体,则只要subject和object实体的首词能匹配上,则对应的实体也能匹配上
![enter description here]()

OneRel: Joint Entity and Relation Extraction with One Module in One Step
论文: https://arxiv.org/pdf/2203.05412
代码: https://github.com/ssnvxia/OneRel
TPLinker存在的问题:
- 在构建实体和关系时,引入了1+2R个矩阵,即一个矩阵用来抽取关系,2R个矩阵抽取subject和object实体对头之间的关系,R个矩阵抽取是梯队尾之间的关系。存在较多冗余的信息,而且忽略了三元组中关系实体、头实体和尾实体相互的关系
![enter description here]()

提出单模块,单步解码的实体关系联合抽取方法
- Multi-Module Multi-Step: 实体和关系分别建模,串行多步解码,会存在误差传递
- Multi‐Module One‐Step: 实体和关系分别建模,单步解码,最后组装成三元组。存在冗余计算
- One‐Module One‐Step: 用单个模块直接建模头实体,关系,尾实体
使用token-pair的方式,用4个标记类型建模三元组 - HB-TB:头实体的开始token与尾实体的开始token 进行连接。
- HB-TE:头实体的开始token与尾实体的结束token 进行连接。
- HE-TE:头实体的结束token与尾实体的结束token 进行连接。
- -:不存在连接关系。

相比TPLinker构建的矩阵数量由1+2R个,减少到R个
在(New York State, Contains, New York City)的三元组中, 关系的矩阵中。解码时通过通过HB-TE,HE-TE可以得到头实体New York State,HB-TB, HB-TE可以得到尾实体New York City
UniRE: A Unified Label Space for Entity Relation Extraction
论文: https://arxiv.org/abs/2107.04292
代码: https://github.com/Receiling/UniRE
- 之前联合学习的方法仍然使用各自的标签空间,并没有将标签空间联合起来
- 将sequence labeling调整为关系抽取任务,将NER和RE两个任务放在同一个标签空间进行处理

- 引入词对关系表,将实体和关系通过该表完整的表示出来(PER:人名实体,GPE:地理位置实体,PER-SOC: 社会关系,ORG-AFF:机构附属关系, PHYS:位置临近关系
- 正向关系:表的上三角部分。人名实体 David Perkins 对地理位置实体 California 存在位置临近关系 PHYS ,那 David 对California,Perkins 对 California 都具有 PHYS 关系;
- 逆向关系:表的下三角部分。人名实体 doctors 对地理位置实体 village 存在隶属关系 ORG-AFF ,那 doctors 对 village具有 ORG-AFF 关系;
- 无向关系:和表对角线对称的。两个人名实体 David Perkins 和 wife 之间存在社会关系 PER-SOC ,这被分解成两个对称关系,David Perkins 对 wife 的正向关系和 wife 对 David Perkins 的逆向关系。实体也可以看做无向的关系,例如,David Perkins 是一个人名实体,那 David 对 David ,David 对Perkins,Perkins 对 David ,Perkins 对 Perkins 都具有标签为 PER 的关系。
模型的训练转换为预测任意两个单词之间的关系,采用双仿射变换




损失函数为交叉墒损失

对该建模的一些约束
对称性: 对称关系具有如下性质,和是等价的。因此满足该条件的两个关系关于对象线是对称的。实体和无向关系关于对角线是对称的。因此,这些标签对应的概率分数应该关于对角线对称。将标签分为y分为对称标签(实体和无向关系)和非对称标签。对于对称标签,具有如下约束:
![enter description here]()
蕴含性: 给定一个关系,则参与关系的必定是两个实体。相反,给定两个实体,他们两个之间不一定存在关系。则关系的概率分布应该不大于参与该关系的两个实体的概率分布


Max为hinge loss。最终的loss

欢迎关注我的公众号!
