半监督学习汇总——分类
半监督学习是机器学习中很常用的一种算法,之前有了解些大概,但没系统性的看过该领域的文章。趁着有空总结了下该领域的文章,由于文章比较多,整理完会分成两部分:
- 半监督学习——分类
- 半监督学习——检测
这篇文章是分类,对半监督学习感兴趣的朋友可以期待下。
背景知识
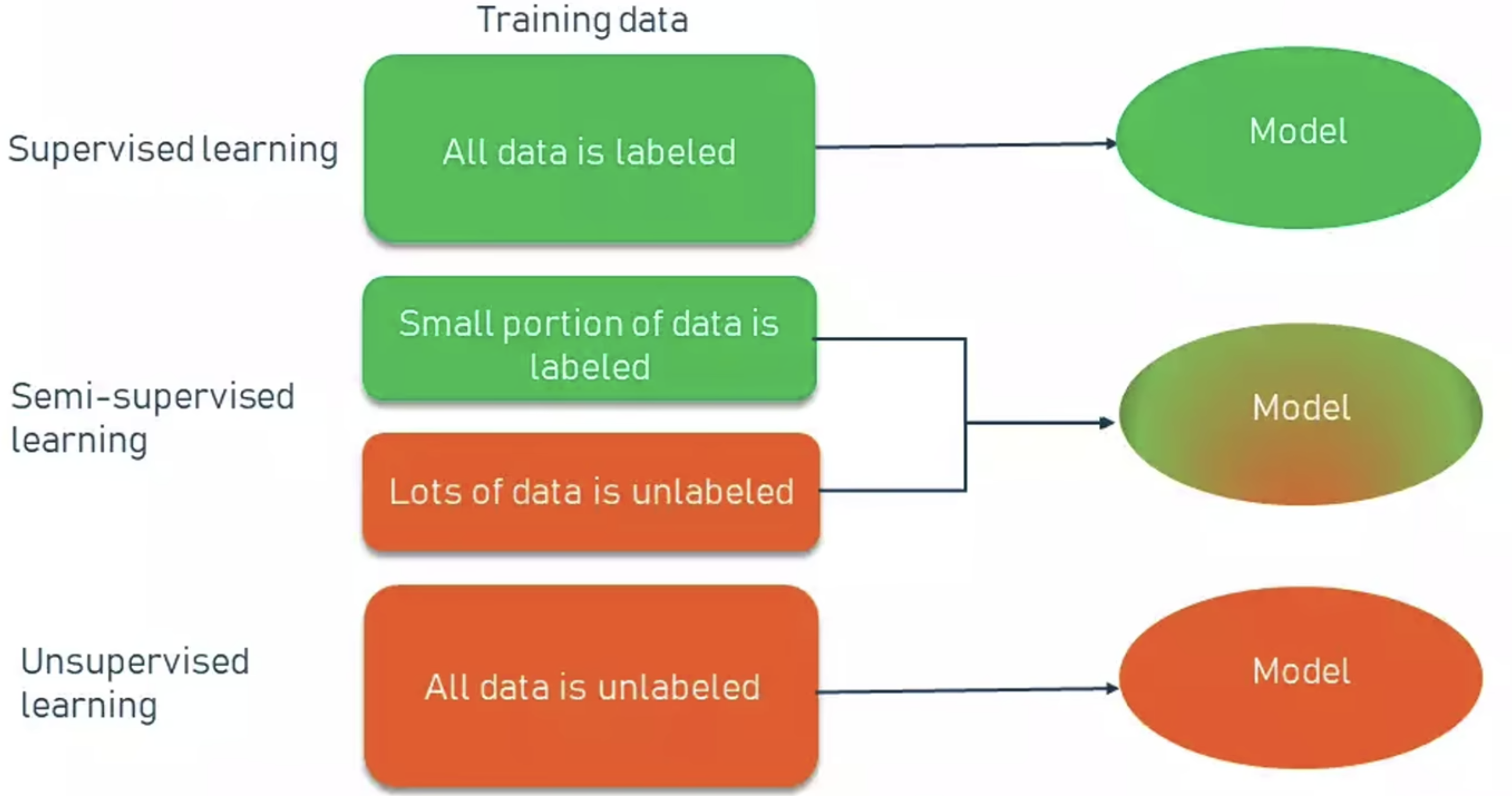
监督算法: 监督算法的训练数据是有标签的,目的是让模型能正确预测数据的标签
无监督算法: 训练数据没有标签,根据数据自身的特性设计模型进行分类
半监督算法: 半监督算法是介于无监督和监督算法之间的一种算法类型。其特点是有少量有标签的数据,以及大量的无标签数据,可以得到只用有标签数据训练更好的结果
π model
π model网络结构如下图所示。因为是半监督学习,既有有标签数据,也有无标签数据,π model将网络分为了两部分:
- 第一部分为图中使用交叉熵损失。该部分为有label的数据$x_i$,$z_i$为模型预测结果,用于和$y_i$比对,使用corss entropy
- 第二部分使用MSE损失。该部分为无label的数据$x_i$,$x_i$会经过数据增广和模型中的drop out,这两部分都是为了引入一定的数据差异。同一个输入经过两次增广和dropout之后得到特征$z_i$和$\widetilde{z_i}$,使用MSE loss,目的是使增广前后的特征尽可能的相似。
两个损失会经过weighted sum配置合适的权重,得到最终的loss
下面是π model的伪代码


Temporal ensembling
论文链接: https://arxiv.org/abs/1610.02242
代码链接: https://github.com/ferretj/temporal-ensembling
Temporal ensembling的方法和π model非常相似,核心思想都是想利用好有监督的数据和无监督的数据,改进的原因是在π model中使用了两次模型增广和推理,耗时比较长,在Temporal ensembling中使用了Temporal的模型,具体而言是使用了之前epoch得到的特征结果去做对比,模型结构如下图:

$\widetilde{z_i}$为之前epoch模型保存的特征,$z_i$为当前模型的推理结果,并且会保存给下一个epoch使用
伪代码如下:

注意, 在更新特征z时,不光用到了当前的特征,也会考虑到之前所有的特征,具体可以看伪代码最后几行
在大量半监督数据上做了消融实验,验证了Temporal ensembling的有效性




Mean teacher
论文链接: https://arxiv.org/abs/1703.01780
代码链接: https://github.com/CuriousAI/mean-teacher
mean teacher的思想和Temporal ensembling也非常相似。改进的原因是在Temporal ensembling中每个epoch才会更新一次对比的特征,在大型的数据集上训练时,用于对比的特征更新的非常慢,时间成本也很高,因此在mean teacher中使用更新模型的方式取代原来更新特征的方式。思想如下图所示

student model即当前模型,teacher model为更新的模型,会参考当前模型和之前模型的权重,得到一个新的模型。更新的方式用公式

目的也是使student mode和teacher model预测出的特征一致
mean teache和之前的工作π model以及Temporal ensembling进行了对比


MixMatch
论文链接: https://arxiv.org/abs/1905.02249
代码链接: https://github.com/YU1ut/MixMatch-pytorch
mixmatch是最小化熵的方法,和前面介绍的三篇一致性正则化法有些差异。最小化熵方法的思想基于机器学习中的一个共识。即分类器的边界边际分布的高密度区域(说人话就是不能从类中心去划分边界)。因此强迫分类器对未标记数据做出低熵预测。实现方法是在损失函数中增加一项,最小化$p_{model}(y|x)$对应的熵。
mixmatch的思想在下图中伪代码展示的很清楚

一个batch中有B份有标签的数据X和B份无标签的数据U
- 将有标签的数据增广一次
- 将无标签的数据增广K次
- 对无标签的数据增广后的结果模型推理后分类,对K个结果取平均,得到模型预测的标签
- 使用temperature sharpening算法,对上一步得到的标签后处理。sharpening算法公式如下:

- 增强后带标签的数据组成一个batch,即$\widetilde{X}$
- 增强后无标签的数据,和预测出的标签组成K个batch,即$\widetilde{U}$
- 将$\widetilde{X}$和$\widetilde{U}$混合,得到新的数据集W
- 应用mixup将增广后有标签的数据$\widetilde{X}$和新的数据W混合得到$X^{‘}$
- 应用mixup将增广后无标签的数据$\widetilde{U}$和新的数据W混合得到$U^{‘}$
得到两个新的数据集后就可以按mixup混合的思路进行训练
sharpening的大致流程如下图所示

接下来是实验结果部分:


ReMixMatch
论文链接: https://arxiv.org/abs/1911.09785
代码链接:https://github.com/google-research/remixmatch
从名字上可以看出ReMixMatch是MixMatch的改进版本。MixMatch中比较重要的思想是猜测无标签数据的标签,使用最小化熵的方法做训练。
ReMixMatch的改进主要包含两部分: Distribution Alignment和Augmentation Anchor。伪代码如下:
- Distribution Alignment。考虑到猜测无标签数据的label有可能存在噪声,因此考虑到使用有标签数据的标签分布,对无标签的猜测进行对齐。对应代码中的第7行。如下图所示,$q_b$对应Label guess。$\widetilde{p}(y)$是一个运行平均版本的无标签猜测,$p(y)$是有标签数据的标签分布。对齐之后的标签猜测如下公式

- Augmentation Anchor。考虑到简单数据增广得到的预测结果会比复杂增广得到的预测结果要更加可信。因此对于一张图片,首先会进行弱增广,再进行多次强增广。弱增广和强增广共同使用一个标签进行mixup和模型训练


接下来是实验结果部分:

FixMatch
论文链接:https://arxiv.org/abs/2001.07685
代码链接:https://github.com/google-research/fixmatch
在FixMatch中没有采用MixMatch系列中有标签数据和无标签数据猜测标签后互相mixup作为训练样本的方法,本身思想和mean teacher及之前方法更相似。FixMatch中的Fix主要强调的是混合两种数据增广方式,分别是弱增广和强增广
弱数据增广的方式:
- 平移
- 反转
- 平移&反转
强数据增广: - cutout
- random augment
- control theory augment
其中若数据增广和强数据增广的前两种方式都比较常见,这里详细说下control theory augment数据增广方法: - 该数据增广方法中有18个候选集,例如旋转,色彩变换等
- 初始化transform的权重$W=[w_1,w_2,…,w_18]$
- 随机选择其中两个增广方法i和j,增广的权重分别为$w_i/(w_i+w_j)$, $w_j/(w_i+w_j)$
- 将两个增广图像混合,更新transform的权重$W$, 第一个公式可以看作MAE损失,第二个公式是用动量的方式更新transform的权重。
![]()

因此可以将control theory augment看作是可以学习的rand augment, 能学习出好的增广方式,使得分类更准确。为什么不用auto augment呢?因为auto augment需要标签作为学习的条件,而半监督中大部分数据都没有标签
对于无标签的数据,会先经过弱数据增广获取伪标签,只有某一类的置信度大于一定的阈值才会执行为标签的生成(下图中红色部分),生成的伪标签用于监督强增广的输出值。

接下来是实验结果部分:
Noisy Student
论文链接:https://arxiv.org/abs/1911.04252
代码链接:https://github.com/google-research/noisystudent
Noisy Student和之前的一致性正则化法也非常相似。区别在于强调了在student模型中加入噪声。在这篇文章中有teacher model和student model的概念。teacher是使用有标签数据训练的模型,student是使用teacher模型预测了无标签数据的标签后,用无标签数据训练的模型。
而Noisy Student强调的是在student模型中加入噪声,teacher模型和student模型可以用不同的模型训练,也可以使用相同的模型。要思考加入噪声的原因,可以假设teacher和student相同结构联合训练的场景,则student模型不加入噪声,则预测结果和通过teacher模型生成的伪标签会完全一致,student模型就失去了更新的动力。所以加入噪声是很有必要的。
Noisy Student的思想如下图所示:

关于student模型使用数据增广和dropout的消融实验如下:

该文章列举了一些消融实验得到的经验,基本都很符合直觉:
- 使用性能好的teacher模型能得到更好的结果
- 大量的无标签数据是必要的
- 在某些场景下,soft伪标签比hard伪标签效果要好
- 大的学生模型很重要
- 数据均衡对小模型很重要
- 有标签数据和无标签数据联合训练效果更好
- 无标签数据:有标签数据的比值越大,该方法越有效
- 从头开始训练student有时比用teacher初始化student效果要好
总结
通过阅读上面的7篇文章,半监督学习大概可以分成3种训练方式,分别是一致性正则(Consistency Regularization Model), 伪标签模型(Proxy Label Model), 一致性正则&伪标签模型
- 一致性正则: 图片增广前后,模型的预测结果应该相同。在该种方法中一般会加入数据增广和dropout,引入随机性,损失函数会使用MSE Loss。例如π model,Temporal ensembling,Mean teacher都是该类型的方法
- 伪标签模型: 先在有标签的数据上做训练,然后预测无标签数据的伪标签;模型的训练包括有标签的训练和伪标签的训练。例如MixMatch、ReMixmatch都是该类型的方法
欢迎关注我的公众号!
