半监督学习汇总——检测
上一篇文章中介绍了半监督学习——分类的一些文章,今天来看一下半监督学习应用在检测领域的一些思路。
STAC
论文链接:https://arxiv.org/abs/2005.04757
代码链接:https://github.com/google-research/ssl_detection/
之前的半监督学习(Semi-supervised learning, SSL)基本应用在分类领域,而STAC是在目标检测领域应用半监督学习的论文, 该细分领域为半监督目标检测(Semi-supervised Object Detection, SS-OD)。其思想和分类中使用的一致性学习比较相似,也分为teacher网络和student网络,思想如下图所示
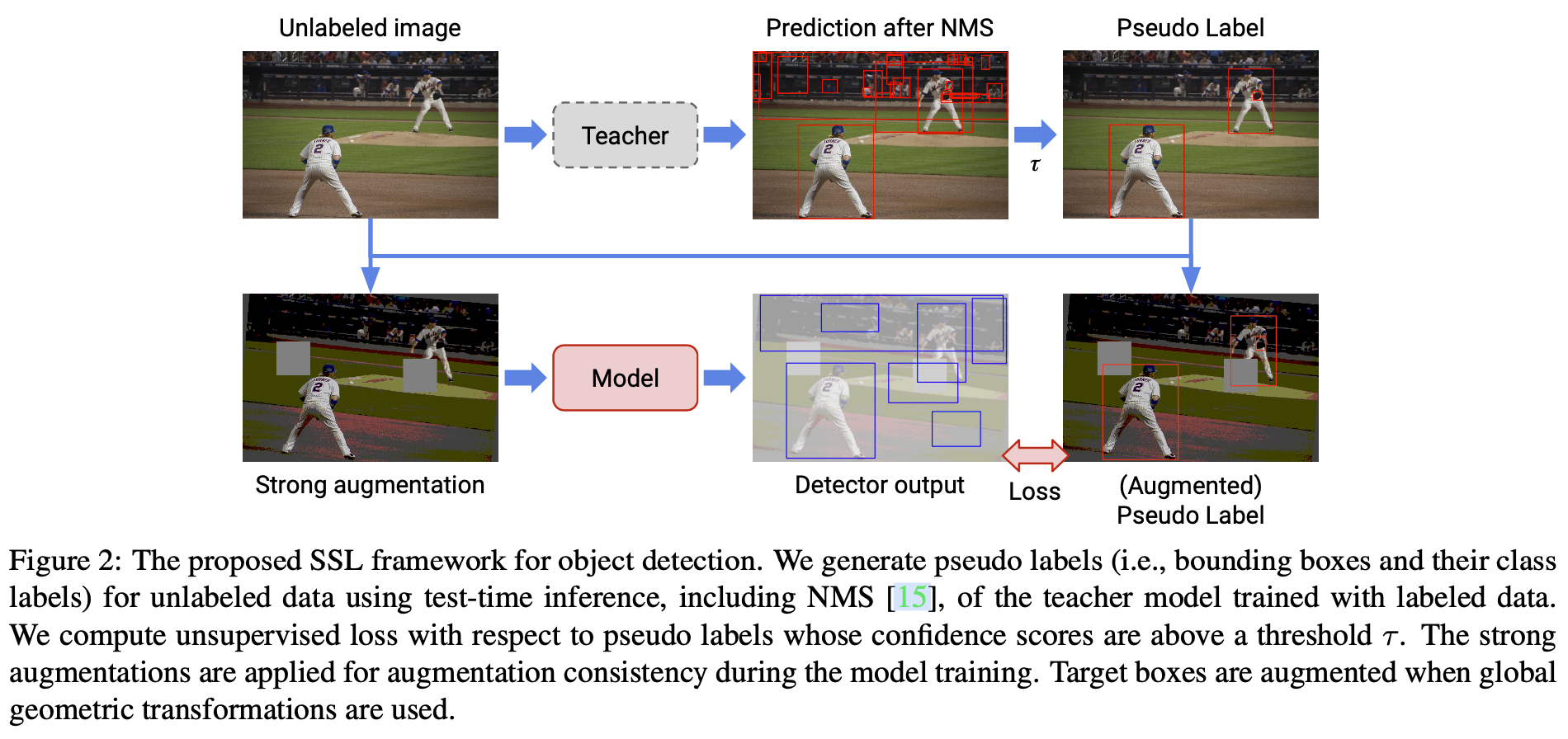
流程如下:
- 用有标签数据训练一个teacher模型
- 用训练好的teacher模型在无标签的数据上生成伪标签(包含bbox,label)
- 对无标签图片应用强数据增广,在几何变换的增广时,bbox也要做相应的增广
- 训练时计算无标签的损失和有监督的损失
下图是应用的一些增广的可视化
下图对比了有监督的模型,增加RandAugment和使用STAC性能的变化
soft teacher
论文链接:https://arxiv.org/abs/2106.09018
代码链接:https://github.com/microsoft/SoftTeacher
soft teacher可以看作是对STAC的改进,STAC的方法简单有效,但是teacher模型和student模型是分阶段训练的。由于student模型会依赖于teacher模型在无标签数据上生成的伪标签,若teacher模型生成了错误且置信度高的伪标签,会造成误差的传递,这也是分阶段训练方式的通病。因此,soft teacher认为端到端训练能取得更好的效果。
soft teacher的网络结构如下图所示:

teacher模型和student模型采用完全相同的结构,其流程为:
- 对于无标签数据,弱数据增广后使用teacher模型,nms后得到检测结果
- soft teacher改进的原因主要是考虑到错误的伪标签对student网络学习非常不利,因此使用了”soft”, 具体而言是使用了可靠性度量作为伪标签的权重,而不是所有的伪标签同等重要。可靠性度量采用的是检测的分数
- 对于分类和边框回归两个任务,分别使用了两种度量方式保证生成的伪标签的可靠性
- 对于分类分支,使用分类置信度作为判断标准,设置较高的阈值能提升分类标签的可靠性
- 对于检测分支, 采用的是box jittering的方式,具体而言,会在候选框周围生成一定偏移量的新bbox,并将新bbox通过teacher模型修正bbox的结果。将该过程重复n次,计算n次修正之后bbox的方差,公式如下。方差越小代表bbox的可信度越高,figuer3(c)的图可以反映方差和bbox预测效果的关系。
![]()

如下图(b)所示, 候选框的定位精度和分类置信度没有很强的相关性,这点在很多检测论文中都有提及并且有优化,例如IOU Net, yolox中的Decoupled head
从实验结果可以看出,相比STAC有较大提升
Dense teacher
论文链接:https://arxiv.org/abs/2106.09018
代码链接:https://github.com/microsoft/SoftTeacher
之前基于伪标签分类具有以下问题:
- Thresholding: 阈值用来区分teacher模型在无标签数据上生成的分类和bbox结果应该如何取舍。作为预定义的数值,阈值非常难选取。设置的较大,会导致召回难以提升;设置的较小,精度会难以提升。
- NMS: NMS的问题和threshold相似,都是预定义的值。设置的较大,会过滤掉一些稍微密集的正样本,较小会有些假正例被保留下来
- Label Assign:

说了之前伪标签这么多的缺点,接下来看看dense teacher是怎么做的。
在dense teacher中提出了密集伪标签(dense pseudo-label, DPL),区别于之前伪标签和有标注数据形式一致。伪标签类似FCOS的中间产物,具体而言将feature map通过cls head输出logits, 再通过sigmoid生成dense label。生成的sigmoid数值是连续的,因此需要使用Quality Focal Loss(Generalized Focal Loss)作为损失函数监督student模型训练。需要注意的是dense label并不是feautre输出的是每个点的分类和回归结果,类似FCOS的训练方式。dense label如下图中绿色区域

DPL中有丰富的信息,但由于没有阈值的过滤,也保留了很多低分的信息。直观上看,这些低分信息对模型帮助很小,这部分区域可以看作难区分的负样本,文中也证明了保留该信息作为监督信号会损害student模型的学习。因此根据teacher模型的特征丰富度得分(Feature Richness Score, FRS),划分learning region和suppressing region。具体的,通过FRS选取top k%的像素作为学习区域,其他区域被抑制为0.
该方法相比之前方法也有一定提升,但由于伪标签的生成和FCOS相似,不太适用于rcnn等两阶段基于anchor的方法

总结
由于目标检测包含了分类和定位两个任务,因此目标检测场景下的半监督学习和分类场景还是非常相似的。整体思路是使用伪标签/一致性的方法对无标签数据监督。STAC将分类中半监督的方法借鉴过来,在检测领域的半监督取得了很好的效果;而soft teacher进一步思考伪标签的合理性,避免teacher模型误差的传播,区别于分类模型,在额外的定位任务上思考如何评估定位的准确性;Dense teacher则思考半监督学习和检测任务中的阈值对模型整体效果的影响,整体思路也借鉴了anchor free的FCOS模型的思想,进一步提升了半监督带来的收益。