CNN版的MAE——SparK
本文首发于公众号“CVTALK”。
论文链接: https://arxiv.org/abs/2301.03580
代码链接: https://github.com/keyu-tian/SparK
背景
MAE是CV领域自监督学习的经典工作之一,其受启发于NLP领域的BERT,和之前在IBOT中有介绍过的BEIT比较相似,区别在于MAE中mask和还原的是像素级的特征,而不是tokenize。

MAE和BEIT中使用的backbone都是transformer,好处在于可以很自然的使用patch embedding,将图片切片为一个个patch,再像BERT中随机的将一些token/patch做mask,学习目标是用上下文的信息还原被mask的部分。
因为BERT和MAE使用的都是transformer,所以在将其思路迁移到CV领域时很直接。而在用CNN实现MAE时,由于CNN和transformer差异较大,会存在很多问题。今天介绍的这篇文章就是将BERT中的思想迁移到CV领域,并且用CNN实现。论文名叫做Designing Bert for Convolutional Networks: Sparse and Hierarchical Masked Modeling(SparK),从标题也可以看出干的事情和解决的方法,下面开始详细介绍。
CNN做MIM的限制
限制主要在如下三方面:
- data distribution shift
- mask pattern vanishing
- Single-scale algorithm cannot learn multi-scale (hierarchical) features.
data distribution shift
data distribution shift可以用下图解释:

上图中,第一行的图是不同Encoding process的方式做MIM,第二行的图和第一行对应,灰色的代表MIM之前的像素分布,蓝色代表MIM之后像素的分布。
- 图a是使用transformer做MIM,可以看到MIM前后像素的分布是一样的
- 图b时使用CNN做MIM,MIN之后相比之前某一种像素的数量会变的非常高
从上图可以看出,CNN做MIM的方式带来了像素分布的变化。造成图a和图b差异的原因:
- 在transformer中,patch embedding的像素被mask掉,网络就不可见该部分信息了,对于网络来说只能看到剩下的信息
- 在CNN中,不能像transformer中自然的做mask。只能采取一种中间的方式,例如将需要mask的像素置为一种特定的颜色(黑或白)。会造成MIM之后mask所置为的颜色,对应的像素数量增多。
mask pattern vanishing
mask pattern vanishing可以用下图做解释

上图的左侧中,用1代表没有mask掉的部分,m代表被mask掉的部分。由于卷积中的卷积核会在特征图上按照滑动窗口的形式更新特征。例如使用33的卷积计算时,原来被mask掉的部分,卷积的时候可以看到部分没有被mask的特征,因此在更新之后的特征,被mask的部分会混入没被mask的信息。随着conv层数的增加,最终得到的特征只剩下没被mask掉的特征。*信息的泄漏会导致网络无法训练。
Single-scale algorithm cannot learn multi-scale (hierarchical) features
transformer和CNN有一个区别是transformer是单尺度的算法,而CNN是多尺度的算法。这是由于来自于NLP的transformer,每个词是具有语义信息的,而在处理图像的CNN中,单个像素往往不具有意义,需要借助卷积核并堆叠多层扩大感受野。并且在CNN的网络中,金字塔的结构往往对图像识别是有效的。
SparK
为了解决CNN做MIM时的一些限制,Spark构建了一个使用稀疏卷积和分层的网络。
sparse convolution
sparse convolution可以用来解决上一节限制中的前两个问题,即data distribution shift和mask pattern vanishing。
sparse convolution来自CVPR 2015的一篇文章Sparse convolutional neural networks。sparse convolution最初是用在3D点云场景的卷积中,由于点云的数据稀疏,无法直接使用标准的卷积,因此会建立哈希表,保存特定位置的特征。关于sparse convolution更细节的信息可以参考这篇博文。

在SparK中,sparse convolution跳过被mask位置的特征,对于卷积来说这部分特征既不是黑也不是白,相当于没有,也就不存在data distribution shift和mask pattern vanishing的问题。
加入sparse convolution后,卷积前后的效果如下图所示:

Hierarchical encoding and decoding
为了学习多尺度的特征,SparK使用了一种分层的网络结构,如下图所示:
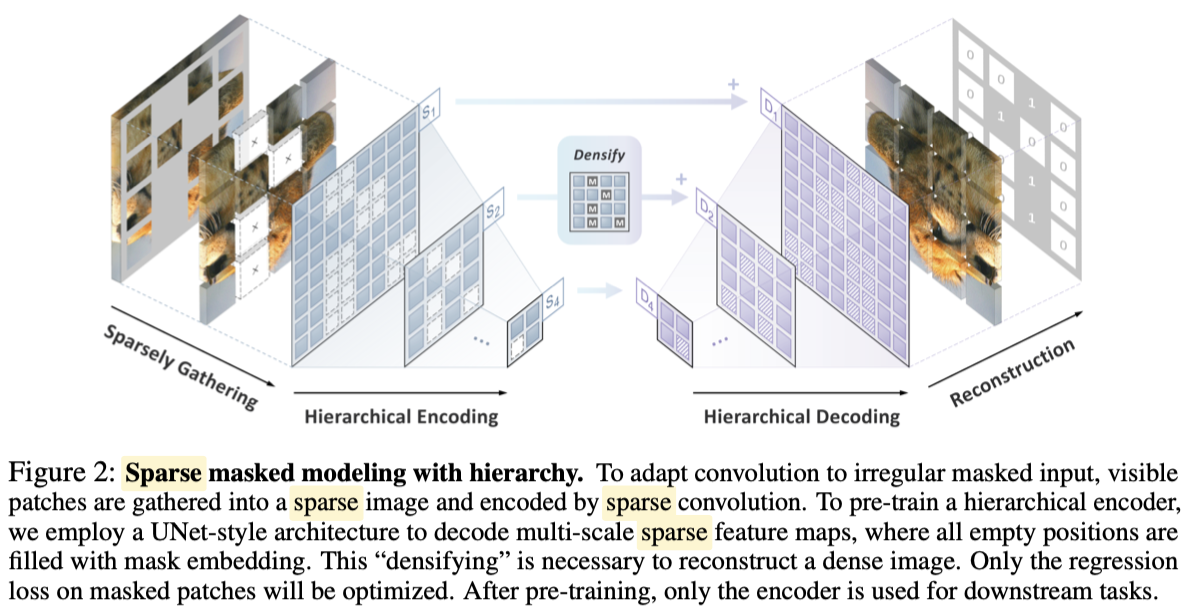
整个网络结构和U-Net比较类似,分为encoding和decoding:
- 会分为四种不同的尺度,分别是原图的4x,8x,16,32x的下采样
- 原图会有部分像素被随机的mask掉,因此特征是稀疏的,为了让CNN学习,会填充特殊的[mask]将特征变得稠密
- 类似U-Net,encoder和encoder之间会有skip connections
- 最终的目标是还原出被mask掉区域的像素
实验
CNN预训练比transformer预训练好
这个结论是从下表得出来的:
- 分别对比了Swin-B和ConvX-B在有监督训练下的效果,两者指标相似,说明两个网络的效果差不多
- Swin-B使用了SimMIM的预训练,ConvX-B使用了SparK的预训练,Spark预训练之后的模型会比SimMIM要好,证明了CNN预训练比transformer预训练好

下游任务的迁移学习
该部分实验将SparK和其他对比学习任务在分类、检测和分割任务上做了对比

SparK预训练的有效性
SparK的训练方式可以扩展到任意CNN的网络中,这一部分主要是证明SparK预训练后的小模型会比没有Spark预训练的大模型效果要好。可以看到ResNet和ConvNeXt的网络结构,经过了Spark预训练后的小模型分类的指标会接近或略高于没有预训练的稍大模型。

可视化
可视化的结果还是挺惊艳的,和MAE中展示的类似,有些图片尽管保留的信息只有非常小的一部分,但仍然能较完整的还原出原图。

结论
SparK的文章还是挺有启发的,到如今BEIT和MAE都是很经典的工作,follow的工作很多。但很少有看到尝试用CNN做类似的事,之前我自己也没深入的思考过为啥CNN不能干。看了这篇文章,感觉对CNN和Transformer的理解有稍微深刻些;
MIM的论文并不少见,但将其在CNN上实现还是挺有意思的。作为一个最开始看着CNN在图像领域大放异彩,到逐渐被transformer超过的老CVer,看到试图让大家再关注CNN的论文还是挺感触的。大趋势上大家都在拥抱transformer,毕竟效果确实好,不过CNN也没有被完全取代,至少在工业界很多场景CNN还是挺普适的,多思考下两者的差异,也能更好的理解技术的发展。