一篇文章搞懂Vit-RGTS
本文首发于公众号“CVTALK”。
论文链接: https://arxiv.org/abs/2309.16588
代码链接(复现版本): https://github.com/kyegomez/Vit-RGTS
动机
这篇文章的动机是发现在LOST算法中,将其中的DINOv1替换为DINOv2,发现效果变得非常差。 进而一步步分析原因,并提出解决方案优化包括DINOv2在内具有共性的ViT算法。
虽然和这篇文章使用的方法关系不大,但还是先简单介绍下LOST算法,可以更好理解DINOv2是哪里变差,影响到了下游任务。
LOST的全称为《Localizing Objects with Self-Supervised Transformers and no Labels》,即使用transorformer的无监督目标检测。受启发于DINO中展示的特征图,在DINO可视化的特征图中,前景目标区域会被激活,很适合做语义分割和目标检测。因此LOST提出了使用DINO特征图做目标检测的算法。 大概思路是在特征图上找到初始的种子点,然后向四周扩散,逐渐找到目标的区域。
LOST需要借助前景目标区域被激活的特征图,DINOv1好用,但替换为DINOv2却效果很差,说明DINOv2的特征图出了些问题。 因此作者使用同一张输入图片,在包括DINO系列在内的有监督和无监督VIT算法上做了特征图可视化。效果如下:

从可视化上看出人意料,但又在情理之中,并不是DINOv2太差,而是DINOv1太好。除了DINOv1外,其他的网络特征图都出现了一些异常的点。并且异常点都不在前景区域,而是平平无奇的背景。
基于这一奇怪的现象,作者做了一系列分析,明确原因后优化了特征图中的这些异常点
分析
Artifacts具有的特性
Artifacts are high-norm outlier tokens
文中将这种具有高范数的异常值称为artifacts。从下图左侧可以看到DINOv2中artifacts的patch相对于其他patch有更高的norm分。右侧中将不同patch的norm分做了统计,其中大于norm分大于150的patch被称为artifacts。

Outliers appear during the training of large models
对不同参数的模型和迭代时间也做了分析,如下图所示,(a)、(b)、(c)的图分别反映出了三个特征:
-artifacts更容易出现在trasnformer的中高层
-随着训练时间的变长,artifacts会变多
-trasnformer越大,artifacts出现的越多

High-norm tokens appear where patch information is redundant
下图表明了artifacts会出现在和周围patch非常相似的地方。

High-norm tokens hold little local information
artifacts包含的局部特征较少。作者用两个实验验证了这个猜想,如下图所示。分别做了position prediction和reconstruction的任务,这两个任务分别是预测token在图像中的位置和重建对应token的像素,都是很依赖局部特征的任务。但从表现上来看,artifacts相对于其他的patch效果要差很多

Artifacts hold global information
既然artifacts包含的局部信息少,又验证了下全局信息,发现artifacts确实是学习到了一些全局的特征。 作者分别在多个数据集上,用[CLS]和normal、artifacts对应的token做了分类任务,发现artifacts对应的token虽然比不上拥有全局特征的[CLS],但比normal的token要好上非常多。

假设和优化
上面提到了artifacts的特点,基于这些特点,作者也作出解释:大的模型和长时间的迭代,会让模型关注到一些冗余的token,将这些token中原来的局部特征替换为能保存全局信息的特征。
按照这种解释,实际上artifacts的token并没有什么问题,出现在冗余的部分,也可以靠其周围的token补充局部信息。但是这种特性会导致在特定任务上的效果变差,例如最开始提到的LOST想使用VIT特征的任务上。
为了优化掉artifacts,借鉴了memory transformer的模块,在训练的时候会加入一些registers toekn,这些token和cls一样是可学习的,但会在训练完之后扔掉。
本文的网络结构如下图所示:
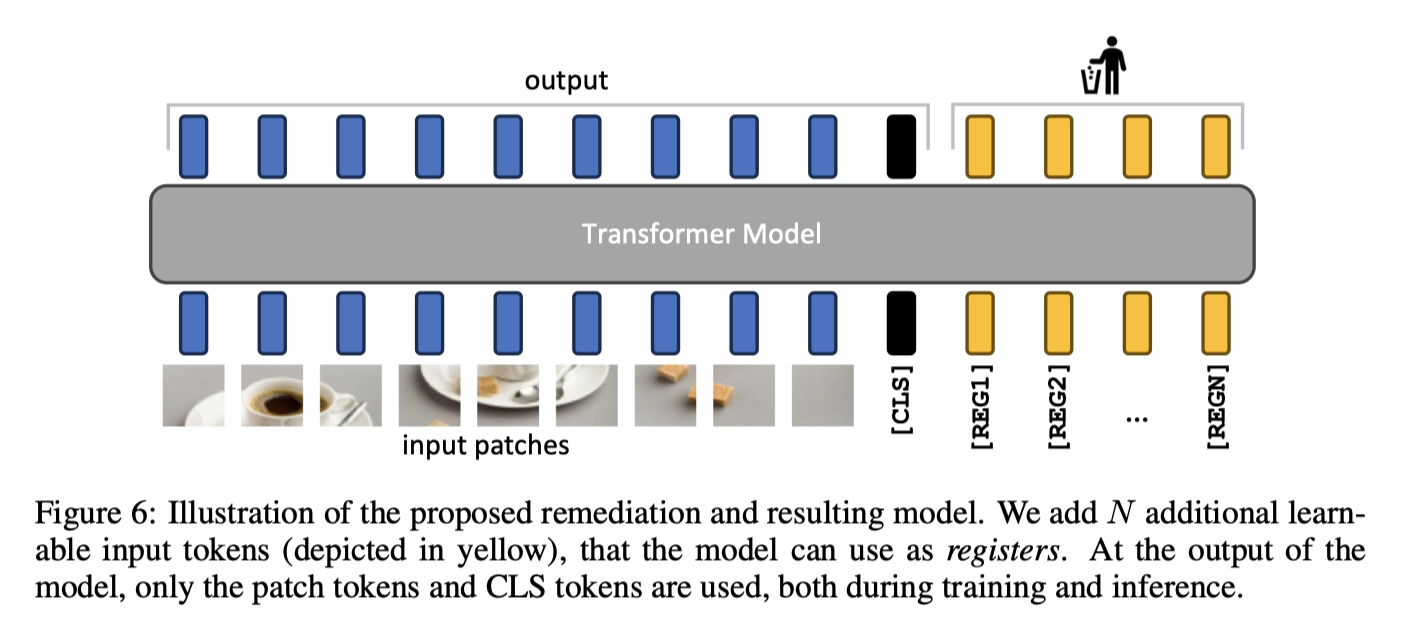
memory transformer提出是为了优化NLP中的翻译任务,在本文中为了避免出现artifacts,新增了一些registers token,希望让网络中的这些registers token学习到全局的特征,而不要让应该学习局部特征的token变成拥有全局信息的artifacts token,训练完成后再将registers token扔掉。
实验
registers token的影响
分别在有监督的DeiT,无监督的OpenCLIP和DINO都做了实验。如下图所示,图(a)是冻结了特征,仅训练linear prob,图(b)是对OpenCLIP做zero-shot。可以发现,使用本文的方法添加registers token前后,效果没有变差,甚至还有略微变好。

并且加了registers token之后,token的norm分布会好很多,不会有artifacts token。如下图所示:

消融实验
reg token的数量

本文的实验中,最重要的一个超参数就是registers token的数量,因此评估了在分类,检测和分割任务上,reg token数量的影响。 在相对密集的任务,即NYUd数据集的语义分割任务上,1个reg token会有较小的效果,作者认为在这种任务上1个足以使artifacts token消失,模型能获得更好的局部特征。而在imageNet的分类任务上,reg token的数量越多越好。
LOST算法的影响
上文的动机部分提到了DINOv2中的artifacts token对LOST之类的算法不太友好,因此也专门评估了使用本文的方法后,DINOv2在LOST上的效果,从下表可以看到是有大幅提升的

Registers的定型分析
这一部分是想判断Registers token学习到了什么样的特征,将拥有全局特征的[CLS]和Registers token的注意力图做了可视化。发现不同于[CLS]激活了所有前景的全局特征,不同Registers token关注的物体会有所不同。
出现这样的情况还是挺有意思的,可惜的是文中并没有做进一步的挖掘分析。

总结
这篇文章并没有在DINO的基础上提点,而是发现了DINOv2的注意力图存在一些异常点,一步步分析这些异常点的特点,最终优化掉这些异常点。虽然没有涨点,但文中发现的一些现象,还是很有意思的。
为什么性能更强的DINOv2会出现在DINOv1中没有的情况,论文中给出的解释是DINOv2训练的时间更长,数据量更大。从artifacts产生的特点来看确实是这样。但从去掉了artifacts前后,在通用的分类,检测,分割等下游任务上,指标并没有什么变化,可以说明artifacts的存在并没有带来负面影响。
模型在学习的过程中,可能觉得相似区域部分的局部特征太简单了,一些不安分的token开始学习“不该”由自己承担的全局特征。而register的引入可以看作是一种解耦的方式,引入特殊的token承担更多的全局信息的角色,避免正常的token“跑偏”。
回到artifacts,感觉还有很多特性可以分析下;而register token,在没有像DETR中加入learnable queries的前提下,不同reg token的注意力图能关注到不同的物体,也很神奇,这一部分文中给出的信息较少不知道是否在所有图像中,reg token是否都有类似的特性。