一篇文章搞懂EVA
本文首发于公众号“CVTALK”。
论文链接:https://arxiv.org/abs/2211.07636
代码链接:https://github.com/baaivision/EVA
EVA是智源曹越团队的文章,也是微软时期swin transformer的作者之一。论文的全称是Exploring the Limits of Masked Visual Representation Learning at Scale。从名字可以看出,EVA试图探索掩码表征学习下模型规模的极限
动机
在EVA中主要对比了之前视觉foundation model两种常用的方式,分别是以BEIT中重建tokenize的和特征蒸馏的方式。BEIT就不赘述了,之前在IBOT的论文中有较详细的写过。下面讲下特征蒸馏的方式。
EVA中所讨论的知识蒸馏文章是之前曹越在微软AI团队参与的工作Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation。这篇文章的出发点是想使用相对MIM要简单不少的特征蒸馏,让student模型获取到和MIM的训练方式有相似性能的模型。下面介绍时将这篇文章简称为Feature Distillation。
Feature Distillation的网络结构如下图所示:

网络的整体架构比较简单,确实相对于MIM是非常简洁的结构:
- 输入: 一张图像,经过两次增广,分别作为teacher和student的输入
- tracher: 一个训练好的网络,可以是CLIP或者DINO
- student: 随机初始化的VIT模型或者swin transformer
- loss: 训练目标是让计算teacher网络输出的特征和strudent网络经过projector head后的特征的L1 loss。期望让student网络的特征和teacher网络的特征相似
论文的整体思路很简单,当然里面也有很多消融实验让蒸馏的效果尽可能好。例如和对比学习的方法中一样,student模型的输出增加了projector head;为了更好的对比不同teacher模型指导蒸馏的差异,将teacher输出的特征做了whitening处理将所有teacher模型的特征归一化到同一量级;VIT中采用相对位置编码,而不是原始的绝对位置编码。
回到EVA的故事,EVA分别验证了MIM中的tokenize和Feature Distillation中的蒸馏方式都不是必要的。
不用toeknize和蒸馏的效果对比如下图所示,图a和b中第一行都是clip作为teacher模型在下游任务上fintune的效果,最后一行都是EVA模型的效果。区别在于图a的二三行使用了tokenize的方式训练了300和1600epoch,但效果都不如没有使用toeknize训练800epoch的EVA,证明了tokenize的方式并不必要;图b中二三行使用Feature Distillation的蒸馏方式训练了300和800epoch,验证了蒸馏时间变长,并没有带来更大的收益,并且也不如同样训练800epoch的EVA,证明了Feature Distillation的蒸馏方式不是必要的。

EVA
论文链接: https://arxiv.org/abs/2303.11331
虽然EVA分别diss了BEIT中的tokenize和Feature distillation中的蒸馏方式,但在实现上EVA还是借鉴了两者,从某些角度理解算是两者的结合。EVA的大致流程如下图所示:
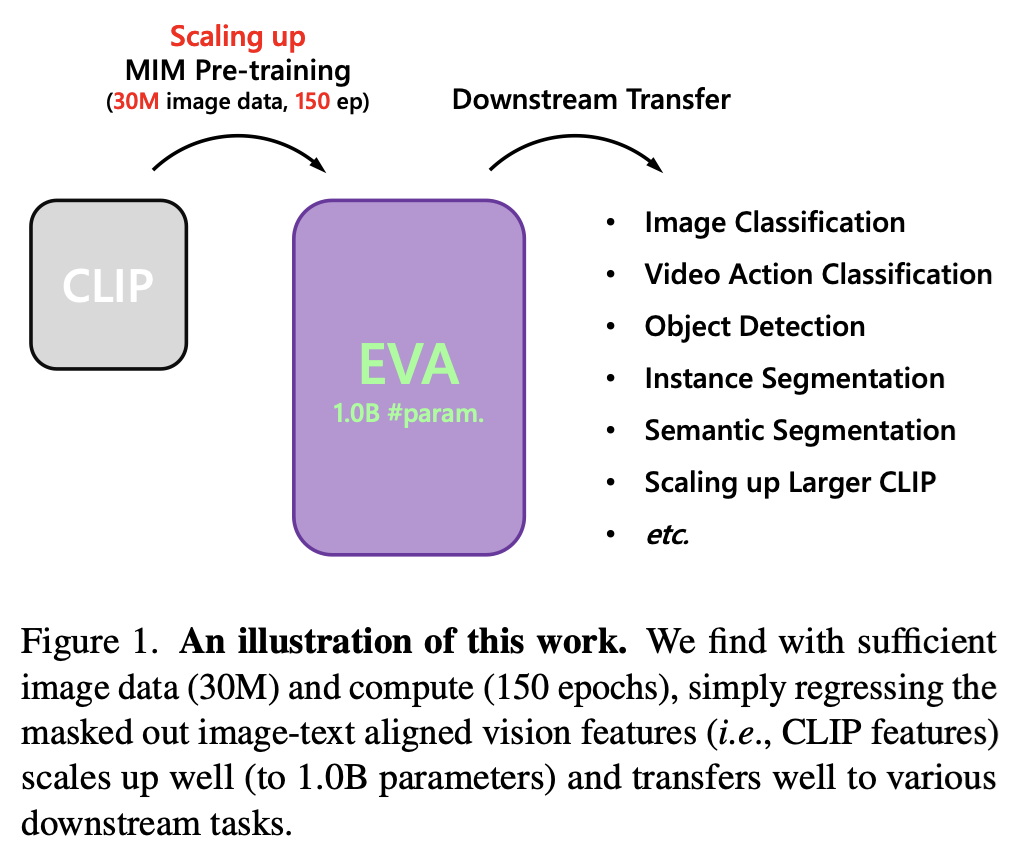
思路也非常简单:
- 输入: 一张图像,经过两次增广,分别作为teacher和student的输入。类似MIM,student输入的图片有40%的patch被mask了
- teacher: 训练好的CLIP网络
- student: 拥有10亿参数的VIT网络
- loss: 训练目标是计算teacher网络和student网络输出特征的余弦相似度,期望两者的特征尽量接近
初看EVA时我也很疑惑,动机中提到了tokenizer和Feature Distillation的问题,但EVA的思路和Feature Distillation还是非常接近的,差异主要有以下几点:
- 数据增广时使用了MIM的思想mask掉一些patch,迫使网络学习遮挡不变的特征;
- student参数规模更大了,VIT达到了10亿;
- 由smooth L1 loss换成了余弦相似度
EVA相关的配置如下图:

值得一提的是10亿参数量的VIT并没有使用太多的训练数据,仅用到了完全开源的3千万的数据,这主要得益于CLIP的teacher模型和MIN的数据增广方式。
实验
分类

图像分类上的结果如上图所示,最上面三行灰色的部分,模型参数量都在10亿以上,效果也是最好的,但使用了大量私有的数据集做训练。下面的结果处了BEIT外基本都在14M的IN-21K数据集上训练,但EVA在相同数据规模的情况下,参数量是最大的,且效果也是最好的。
文中也对比了在不同数据集上的鲁棒性

视频动作识别

在视频的任务中表现的也很出色
目标检测和实例分割

目标检测和实例分割都是刷榜很严重的任务了,EVA在其中的表现也都挺好。
EVA-02
这里顺便也介绍下EVA-02,因为改动并不算大,结合EVA-01的工作会能加深印象。主要差异有以下几点:
- VIT的网络结构做了大量的消融实验,包含norm,参数初始化,FFN,位置编码方式


- teacher模型由CLIP换成了EVA-01
- 数据量由3千万到4千万
- 参数量更少由10亿到3亿,但性能有提升

EVA-02包含5种参数量的模型

整体效果相比EVA-01实现了全方位的提升

总结
蒸馏方向的论文,基本都是为了让一个小的student网络在不损失太多性能的前提下,学习到大的teacher网络的特征。
而在大模型时代,EVA探索了student网络能达到的规模上限,并且在测试集上效果略微超过了teacher网络。伴随着EVA-01的成功,EVA-02做了更精细的调整,并且为了变得“可用”,参数量做了大量的缩减,而性能相比EVA-01有明显的提升。
为什么EVA蒸馏后的网络会比teacher网络有更好的效果呢?个人感觉是CLIP确实足够强大,而且EVA中student网络的MIM训练方式足够的好。具体而言CLIP在4亿的图文对上做了预训练,输出的图像特征和语言的特征做了对齐,是一种高维的语义信息,而VIT作为一个backbone,更利于提取到低维的结构特征,并且MIM的方式迫使VIT学习遮挡不变的特征,最终的特征具有了很好的鲁棒性。