BLIP2——优化多模态训练成本
论文链接: https://arxiv.org/abs/2301.12597
代码链接: https://github.com/salesforce/LAVIS/tree/main/projects/blip2
DEMO链接: https://blog.salesforceairesearch.com/blip-bootstrapping-language-image-pretraining/
前言
BLIP2是BLIP的续作,解决的是多模态大模型训练成本越来越高昂的问题。在多模态模型中,参数量和计算成本比较高的分别是image encoder和text encoder。
前面的相关文章介绍了ALBEF和BLIP,在这篇文章的开始会先了解下BLIP2的大概结构和改动。
在BLIP2中为了减少计算成本,将image encoder和text encoder的部分冻结;提出了轻量级的Q-Former模块,对齐图像和文本的特征。
BLIP2提出了一个两阶段的预训练任务,如下图所示:
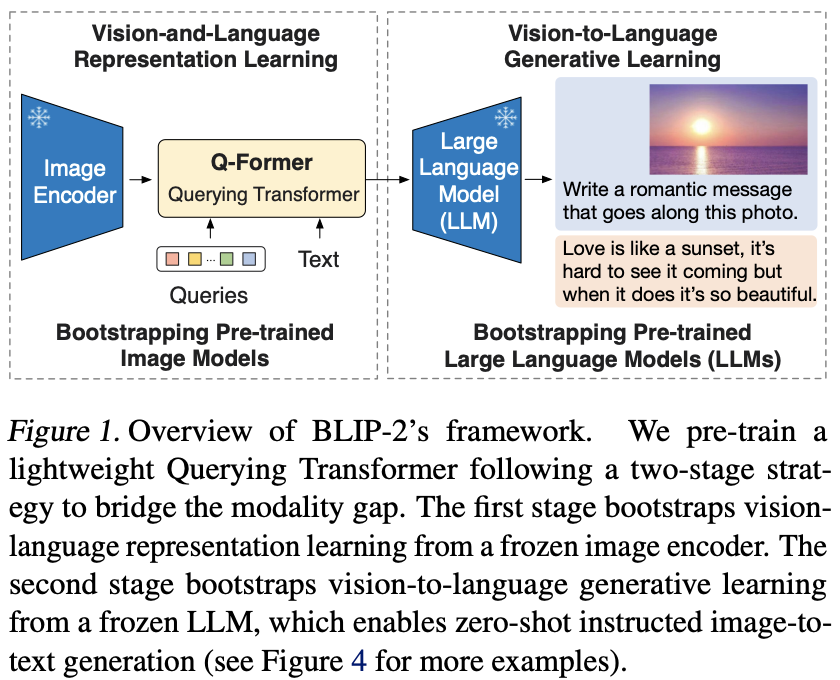
- 第一阶段: Vision-and-Language Representation Learning。表征学习,用Q-Former对齐Image Encoder和LLM之间的特征
- 第二阶段: Vision-to-Language Generative Learning。生成学习,Q-Former提取到和文本最相关的图像特征,结合图文使用LLM获取其文本生成的能力。
Method
Model Architecture
Q-Former的结构和预训练任务如下图所示:

Q-Former中包含两个Transformer:
- 与被冻结的Image Encoder交互提取视觉特征的image transformer,输入包含可学习的Quires和Image Encoder的输出特征。
- 可以作为text encoder也可以作为text decoder的text transformer
Q-Former的参数初始化通过BERTbase,而cross attention层随机初始化。Q-Former的总参数量为1.88亿。Q-Former中包含32个queries,纬度为768,而Image Encoder在结构为ViT-L/14时输出的特征维度为(257, 1024)。在预训练的时候会迫使image Encoder和Q-Former的bottleneck结构通过learned queries提取到和文本最相关的视觉信息。
Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
该阶段的目的是训练Q-Former,使其可以提取到与提供文本最相关的视觉特征,和BLIP类似包含三个预训练任务:
- Image-Text Contrastive Loss(ITC): 图像-文本对比学习,对齐图像和文本特征
- Image-grounded Text Generation(ITG): 用于做image caption任务,和BLIP中的LM任务的差异在于图像特征的来源并不是image encoder,而是learned queries
- Image-Text Matching (ITM): 判断图像和文本是否匹配,用于对齐特征
这些任务会共享参数,由于任务的差异,为了避免信息泄漏,query token和text token之间有不一样mask的策略:

- ITM: 为了做匹配任务,在该任务中使用的是Bi-directional Self-Attention, 需要知道图像和文本彼此的特征才能做查询,因此不需要mask。
- ITG: 在该任务中,需要用生成描述图像对应的文本。为了避免信息泄漏,query不能看到文本的内容,因此做query的时候,text的部分需要mask;而在文本生成的部分,只能看到之前已经生成的文本,未生成的部分也需要mask。
- ITC: 在该任务中,可以参考Figure .2,learned queries和input text分别经过self attention和MLP之后做对比学习任务,为了避免信息泄漏,Q和T之前彼此需要mask。
Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
在该阶段的目的是连接Q-Former和冻结参数的LLM,获取LLM的文本生成能力。如下图三所示,包含两个预训练任务。

使用全连接层讲Q-Former输出的特征对齐到和LLM相同的维度,Q-Former提取的视觉特征用来约束LLM的生成,可以为LLM提供最有用的视觉信息。Q-Former的存在避免了为了对齐图像-文本特征而训练LLM带来的灾难性遗忘的问题(catastrophic forgetting problem)。
该阶段的预训练任务包含两个:
- LLM Decoder: 根据Q-Former提供的视觉表示从投开始生成文本
- LLM Encoder+LLM Decoder: 将文本拆分成两部分,前缀文本和Q-Former的特征通过编码器,解码器用于生成剩下的文本
Experiment
Instructed Zero-shot Image-to-Text Generation

BLIP2的框架能够有效的让LLM理解图像,并且保留文本生成能力。下图中展示了在visual knowledge reasoning、visual commensense reasoning、visual conversatio、personalized image-to-text generation等方面的可视化能力

Image Captioning
在image caption任务上微调了BLIP模型,”a photo of”作为LLM的初始输入。在微调过程中冻结LLM,更新image encoder和Q-former的参数。使用了COCO训练数据做微调,并在COCO的测试集测试效果,也在NoCaps验证集上作了zero-shot的实验.
结果如下表所示,BLIP2在NoCaps数据机上达到了SOTA,表明了对out-domain的数据也有很好的泛化性。

Visual Question Answering
使用了VQA数据集微调,和Image Caption任务一样,在微调过程中冻结了LLM,更新image encoder和Q-former的参数。LLM的输入是Q-Former的输出和问题,需要生成答案。为了提取与问题更相关的图像特征,在Q-Former的text-encoder中会将问题作为输入,用于引导Q-Former中的Cross attention产生和问题相关的图像特征。下表展示了VQA任务上的效果.

Image-Text Retrieval
使用了COCO数据微调,由于图像-文本检索任务不需要LLM的生成能力,因此该任务只需要对Q-Former相关的模块微调。对比如下:

ITC和ITM对图文检索任务非常重要,但ITG任务的添加也会带来收益,原因是可以让queries生成和输入文本最相关的特征,提高视觉特征的xiaoguo 。

总结
BLIP2论文中最关键的部分在于Q-Former。在初看BLIP2时让我想到了将transformer应用到目标检测领域的DETR,DETR中的decoder部分的输入包含object queries。关于obejct queries究竟学到了什么在DETR中有简单的说明:

DETR中object queries的实现:1
self.query_embed = nn.Embedding(num_queries, hidden_dim)
100个隐藏层维度为256的embedding,每个query中注入了不同object的位置信息和类别信息。
Q-Former中的learn queries也是类似:1
self.query_tokens = nn.Parameter(torch.zeros(1, config.num_query_tokens, config.qformer_config.hidden_size))
32个隐藏层维度为hidden_size的embedding,每个query用于编码和文本最相关的视觉特征。