BLIP——统一理解与生成的多模态模型
本文首发于公众号“CVTALK”。
论文链接:https://arxiv.org/abs/2201.12086
代码链接:https://github.com/salesforce/BLIP
作者blog链接:https://blog.salesforceairesearch.com/blip-bootstrapping-language-image-pretraining/
前言
BLIP的来源于标题中的Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation。从标题可以看出来BLIP也是文本-图像的预训练模型,并且目的是统一视觉-语言的理解和生成任务。同时支持和理解&生成任务正是BLIP和之前任务的差异。
BLIP可以看作是ALBEF的续作,一作是同一个人,并且都是多模态的领域,多模态任务展现出了比单模态更好的效果,但存在一些局限性:
- 模型角度: 目前多模态的任务主要分为两种,分别是encoder-based model和encoder-decoder model, 都存在一些问题
- encoder-based model: 典型代表是CLIP, 因为预训练的时候没有生成任务,所以在下游任务中很难支持生成任务。例如CLIP不能完成image caption任务.
- encoder-decoder model: 典型代表是SimVLM,该类方法目前在图文检索任务中的效果非常差
- 数据角度: 通过互联网上爬取到的图像文本对,含有很多噪声
相对于ALBEF,BLIP中提出了MED和CapFilt两个模块解决上面提到的两个局限性
BLIP
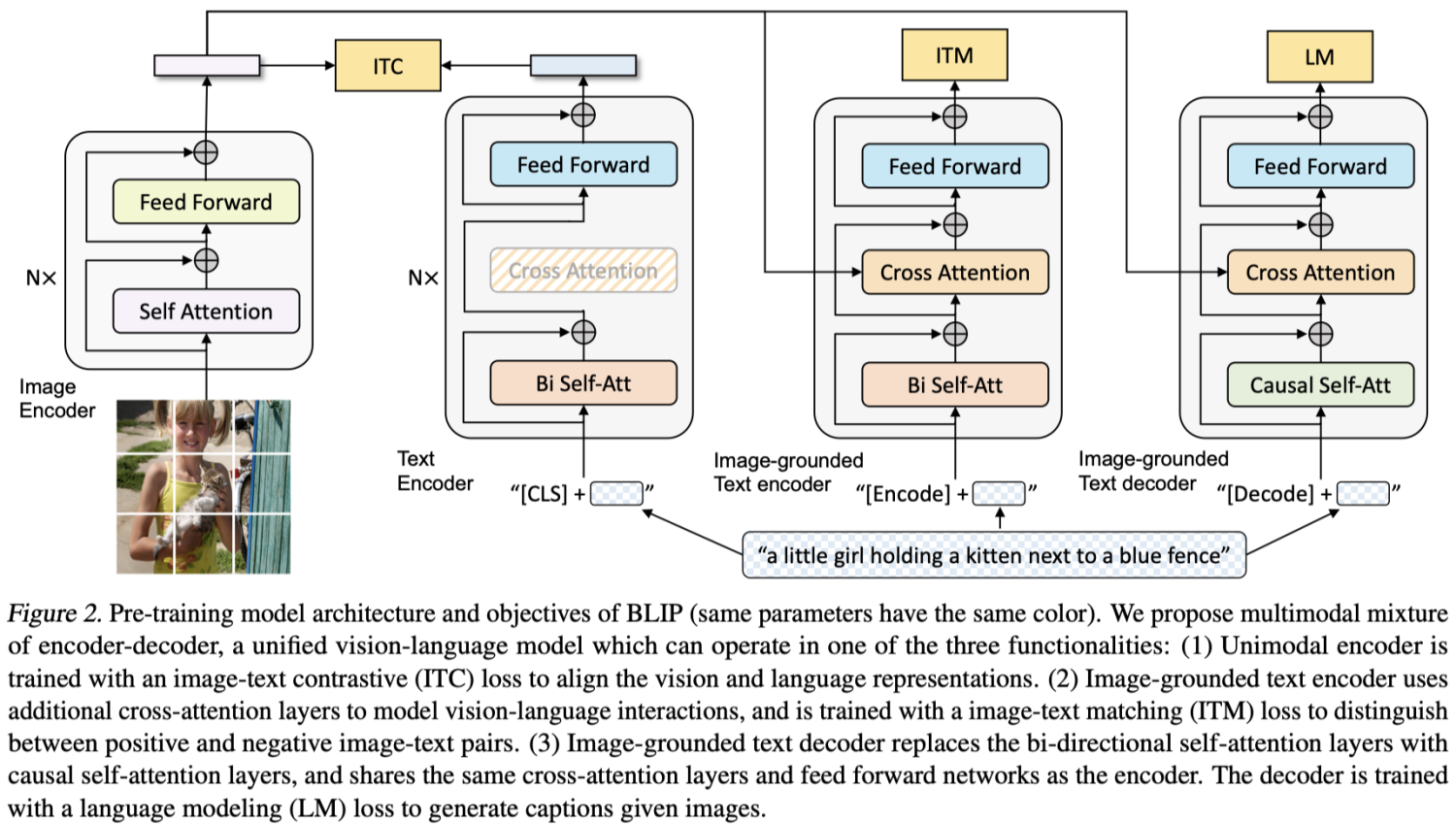
BLIP的网络结构如上图所示, 还是和ALBEF一样,将其拆分为几个部分。BLIP网络的构成包含3个encoder和1个decoder、3个预训练任务还有数据相关的CapFilt模块
Model Architecture
MED的全称是multimodal mixture of encoder-decoder,即包含encoder和decoder的多模态融合,encoder的任务可以做多模态的理解,而decoder任务可以做多模态的生成。分别有以下部分:
- 单模态encoder: 该部分包含两个encoder,分别是image encoder和text encoder,也是Figure 2中的前两个模块。分别对使用VIT和BERT提取图像和文本的特征。
- 基于图像的文本encoder: 该部分和Text encoder的区别在于引入了image encoder产生的特征做cross attention。因为包含图像和文本特征,会用来做图像文本匹配(ITM)任务
- 基于图像的文本解码器: 该部分和基于图像的文本encoder的区别在于将自注意力层替换为了因果自注意力层。用于做语言模型(LM)的任务.
需要注意的是text相关的encoder和decoder有三个,text encoder和Image-grounded Text encoder的共有结构特征是共享的,为了标记差异,在文本的开头分别用”[CLS]”和”[Encoder]”标记。而Image-grounded Text decoder中使用”[Decoder]”
Pre-training Objectives
在预训练中有三个优化目标,有两个基于理解的预训练任务和一个基于生成的预训练任务组成。计算量比较大的image encoder只需要运算一次。
Image-Text Contrastive Loss(ITC)
该部分和ALBEF中一致,目的都是为了对齐视觉和文本模态的特征,并且也使用了momentum encoder产生伪标签作为监督信号。在代码实现上也和ALBEF中的ITC loss完全一致
Image-Text Matching Loss (ITM)
该部分同样了ALBEF中一致,训练目标都是判断图像和文本是否匹配,并且也挖掘了难负样本。代码实现上也和ALBEF中ITM loss的计算完全一致

Language Modeling Loss (LM)
该部分不同于ALBEF中的LM loss,在ALBEF中参考的是Bert中的完形填空任务,目的是完成语言模型的训练,并且能对齐图像和文本的特征。但和Bert类似的任务用途是做语义的理解,并不能做生成任务。因此在BLIP中更类似于GPT中预测下一个token的任务,区别在于BLIP中做的是image caption的任务,即生成图像对应的文本描述。在LM中和ITM中共享了具有共同结构的参数,可以提高模型训练效率,也能从多任务学习中获益.

CapFilt
在ALBEF中也讨论了用于预训练的图像-文本对是从互联网上获取,但这部分数据质量不高,在ALBEF中使用了momentum distillation产生软标签减小噪声数据的影响。momentum的trick在BLIP中也有,但BLIP中有更进一步减少脏数据的影响——试图将预训练数据的质量变高。粗略的理解可以看下图Figure 1,在MED的预训练任务中包含生成字幕的预训练任务也有判断图文是否匹配的预训练任务,因此可以让模型生成图片的描述(Captioner),再通过Filter用于判断图像和文本是否匹配。在图1中,原始的图文不匹配,在最终预训练时会被过滤掉,而Captioner生成的文本和图片匹配,则在最终预训练时会保留生成的数据。

更具体的CapFilt可以参考下图,原始的数据集包含两部分:
- 互联网上收集的(Iw,Tw),存在脏数据
- 人工标注(Ih,Th), 可以认为是干净数据
在Model pretraining模块中会使用包含互联网收集和人工标注两部分数据用于MED部分的预训练,然后会只使用人工标注的干净数据做不同预训练任务的微调:
- 只微调MED中的ITC&ITM任务,让模型有更好的图像文本理解能力,用于在Filtering。判断图像和文本是否匹配,文本的来源可以是互联网收集的和图像匹配的文本,也可以是captioning生成的文本
- 只微调MED中的LM任务,让模型有更好的生成字幕能力
经过Filtering后会保留下来的数据有三部分:
- 人工标注的数据(Iw,Tw)
- 互联网收集的图像和文本匹配的数据(Iw,Tw)
- Captioner生成的和图像匹配的数据(Iw,Ts)

Experiments and Discussions
Effect of CapFilt
关于CapFilter的效果在下表Table 1中可以看到,分别使用Captioner和Filter都可以提升下游任务上的效果,并且增大数据集的规模,提升会更明显。

下图展示了互联网上搜集到的文本和Captioner生成文本数据中一些噪声的示例。

Diversity is Key for Synthetic Captions
这一部分将CapFilt中Captioner生成字幕采取nucleus sampling(top-p)和beam search两种解码方式的差异,对比如下

Nucleus的方式效果更好,相比Beam search的方法,前者生成的文本更加多样(不过也带来了更多的噪声数据)
Parameter Sharing and Decoupling
在预训练阶段,使用14M的数据做预训练。与不共享相比,共享除了Self Attention之外的能获得更好的效果,也能减少模型参数量,提升效率。而如果SA和CA层共享,由于编码和解码任务的冲突,模型的能力会变差

在CapFilt阶段,下表中研究了captioner和filter保持和预训练中一样的参数共享方式或者解耦的差异,结果保持一样的参数共享方式,性能会有退化。作者将其归因于confirmation bias。因为如果Captioner和Filter也存在参数共享,Captioner生成的字幕会变得不容易被Filter判断为有噪声的数据。

Comparison with State-of-the-arts
主要比较了几个多模态的任务:
- Image-Text Retrieval

- Image Captioning

- Visual Question Answering (VQA)
- Natural Language Visual Reasoning (NLVR2)

- Visual Dialog (VisDial)

- Zero-shot Transfer to Video-Language Tasks

总结
BLIP和ALBEF的结构很相似,但关注点从除了单模态和多模态特征融合到开始关注文本的生成能力,其中一个预训练任务从类似Bert替换成了类似GPT,也顺应了NLP领域中的这一趋势。并且和其他大模型一样,更加关注数据的质量,用CapFilt模块获取了质量更高的数据。