ALBEF:Align before Fuse
本文首发于公众号“CVTALK”。
论文链接: https://arxiv.org/abs/2107.07651
代码链接:https://github.com/salesforce/ALBEF
作者Blog链接:https://blog.salesforceairesearch.com/align-before-fuse/
前言
语言和视觉是人类感知世界的两个最基本的渠道,因此多模态的算法里经常会将语言和视觉的模态结合。这一类方法被称为VLP(Vision-and-Language Pre-training)。然而现有的方法主要有以下局限.
之前多模态的方法大致可以分为两类,一类例如VL-Bert等,重点在于使用transformer作为encoder获取图像和文本交互的特征,由于视觉文本特征在transformer之前并没有对齐,因此在transformer任务中获取交互特征很具有挑战。为了让模型更容易学习交互特征,这类方法往往需要高分辨率的图像作为输入,并且需要预训练目标检测器(在ViLT中尝试移除目标检测器,但效果有明显下降)。这类方法在需要结合视觉和文本的推理任务上效果较好,例如NLVR和VQA等任务中。
第二种方法例如CLIP和ALIGN,重点在于分别学习图像和文本模型的任务,做特征对齐,使用对比学习让两个模态的特征都具有其他模态的信息。这类方法在图像-文本的检索任务上表现良好,但由于相比第一种方法缺乏图像和文本的交互特征,在更复杂的图像-文本交互任务上表现一般。
在作者的blog中提到了之前方法的另外一点局限性:
预训练的数据主要来源于互联网,数据来源并不干净。MLM等任务容易对噪声过拟合,从而影响到最终的特征。
ALBEF
ALBEF的名字来源于ALign the image and text representations BEfore Fusing。论文的标题中也强调了Align before Fuse。区别于其他多模态方法,这篇文章提出在融合视觉-文本两个模态的特征之前,先做不同模态之间特征的对齐。出发点结合了上文提到的两类VLP方法的优点,并且减缓了脏数据对预训练的影响。
ALBEF的网络结构如下图所示:
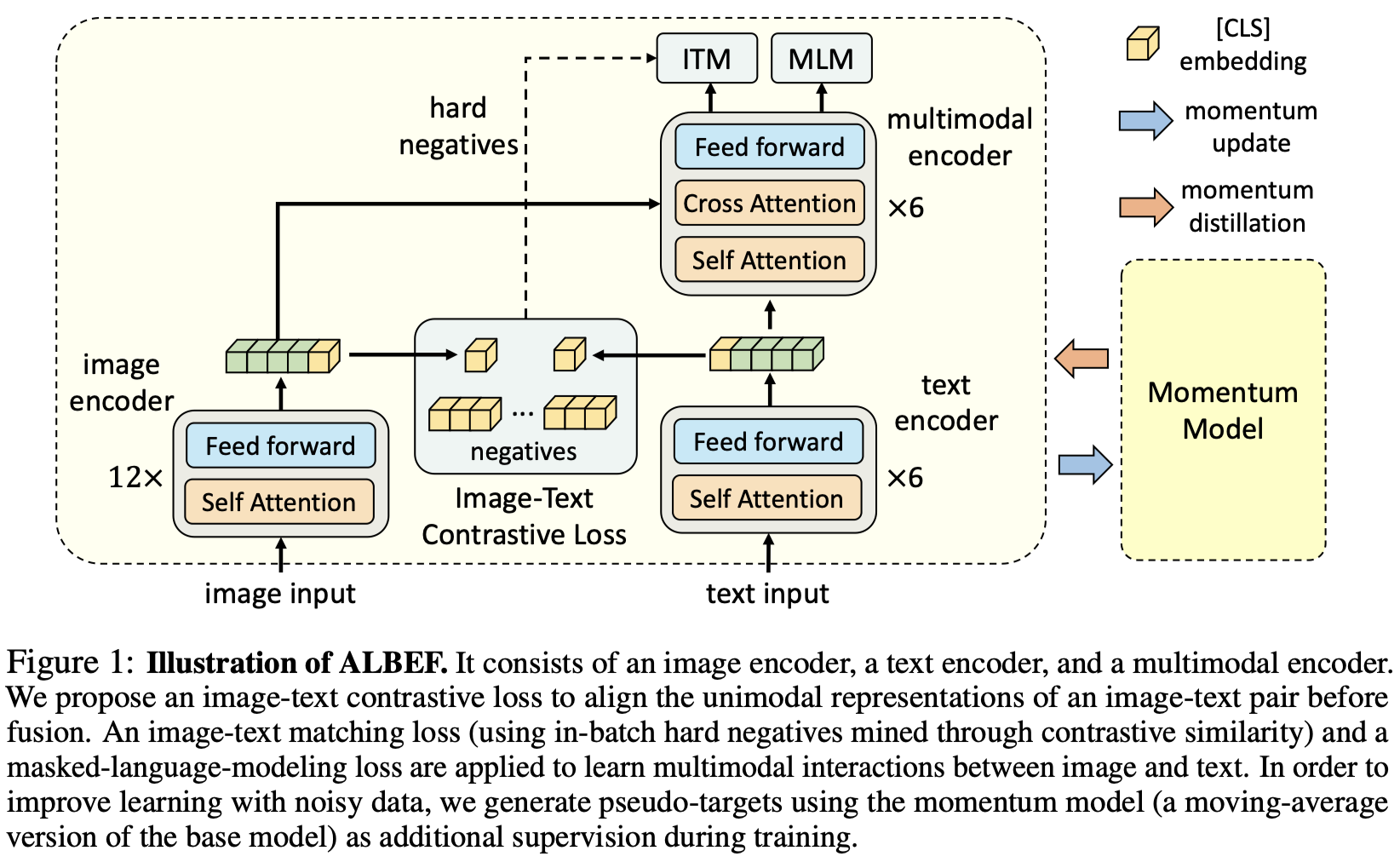
ALBEF的结构并不复杂,弄清楚几个模块和loss也就明白其中的奥妙了。ALBEF包含3个encoder、3个loss和动量蒸馏模块。
Model Architecture
encoder部分如下:
- image encoder: 12层的ViT-B/16
- text encoder: bert中的前6层
- multimodal encoder: Bert中的后6层,因为不同特征间需要attention,相比另外两个encoder多了cross attention的结构
Pre-training Objectives
训练目标主要包含三个预训练任务:
- image-Text contrastive learning(ITC): 目标是在特征融合前对齐视觉和文本的特征以获取更好的单模态特征。受启发于moco,维护了两个队列分别存储动量编码器中的图像和文本特征。使用infoNCE loss分别计算image-to-text和text-to-image的损失。具体可以看下代码


- Image-Text Matching(ITM): 预测图像和文本是否匹配。一般的ITM任务相对简单,loss能降到非常低,ALBEF为了让这项预训练任务变得更有意义,挖掘了困难的负样本。具体做法是在ITC任务中infoNCE loss有相似度的信息,选取和相似度最高,但不匹配的样本作为负样本。损失函数是交叉熵损失。

- Masked Language Modeling(MLM): 训练语言模型。随机将15%的文本mask,利用图像和文本的上下文还原mask的区域,使用交叉熵损失。为了避免脏数据的影响,使用的是伪标签。具体而言存在teacher模型,从student模型采用指数滑动平均(Exponential Moving Average, EMA)的方式更新其参数,而student模型的学习标签是teacher模型预测的embedding。

动量蒸馏
由于预训练的图像文本对基本都来自互联网,存在脏数据。一般表现在文本中包含图像中没有的信息,或者图像中包含文本没有的信息。对于MLM和ITC任务会有较大的影响。因此受启发于moco,使用动量更新的方式构建teacher网络,利用teacher网络产生的伪标签作为监督信号。具体的实现方式可以参考上面ITC和MLM的代码。
实验
评测场景
预训练好的模型应用在了5个场景,用于评估效果:
- Image-Text Retrieval: 包含两个任务,图像到文本的检索和文本到图像的检索
- Visual Entailment: 视觉推理任务,预测图片和文本的关系是包含、中立还是相反的。
- Visual Question Answering: 提供图片和问题,预测答案
- Natural Language for Visual Reasoning: 预测提供的文本是否描述了图片
- Visual Grounding: 在图像中定位出文本中描述的物体的坐标
Evaluation on the Proposed Methods
展示了ALBEF使用不同模块在下游任务上的效果

Evaluation on Image-Text Retrieval


上面的图分别展示了微调和zero-shot在图文检索任务和之前方法的对比
Evaluation on VQA, NLVR, and VE

使用4M的图片做预训练取得了比之前模型更好的效果,并且数据集增大到14M性能普遍有进一步提升。并且由于没有使用检测器,并且输入图片分辨率更低,推理耗时比VILLA减少10倍
Weakly-supervised Visual Grounding




在不同任务上可视化cross attention的特征图,和文本描述的区域匹配
Ablation Study

研究了在文本-图像检索任务上困难负样本在图文检索任务上的影响

在NLVR任务中研究了文本分配(text assignment, TA任务)和不同特征共享方式的影响,细节配置可以看文章的第五部分(Downstream V+L Tasks)
总结
ALBEF比之前多模态的方法效果好有几个关键点:
- 在融合不同模态特征前,做了特征的对齐
- 使用momentum distillation避免了噪声数据在预训练的影响
- 区别于之前ITC任务使用了难负例
并且由于没有目标检测器,下游任务使用时使用更小的图片输入,耗时会极大的缩小