长尾优化汇总
背景
经典的深度学习数据集

Mnist: 数据规模较小,10个类别
ImageNet: 百万数据量,1000个类别
两者的共同点:类别是均匀分布的
真实场景中的深度学习任务
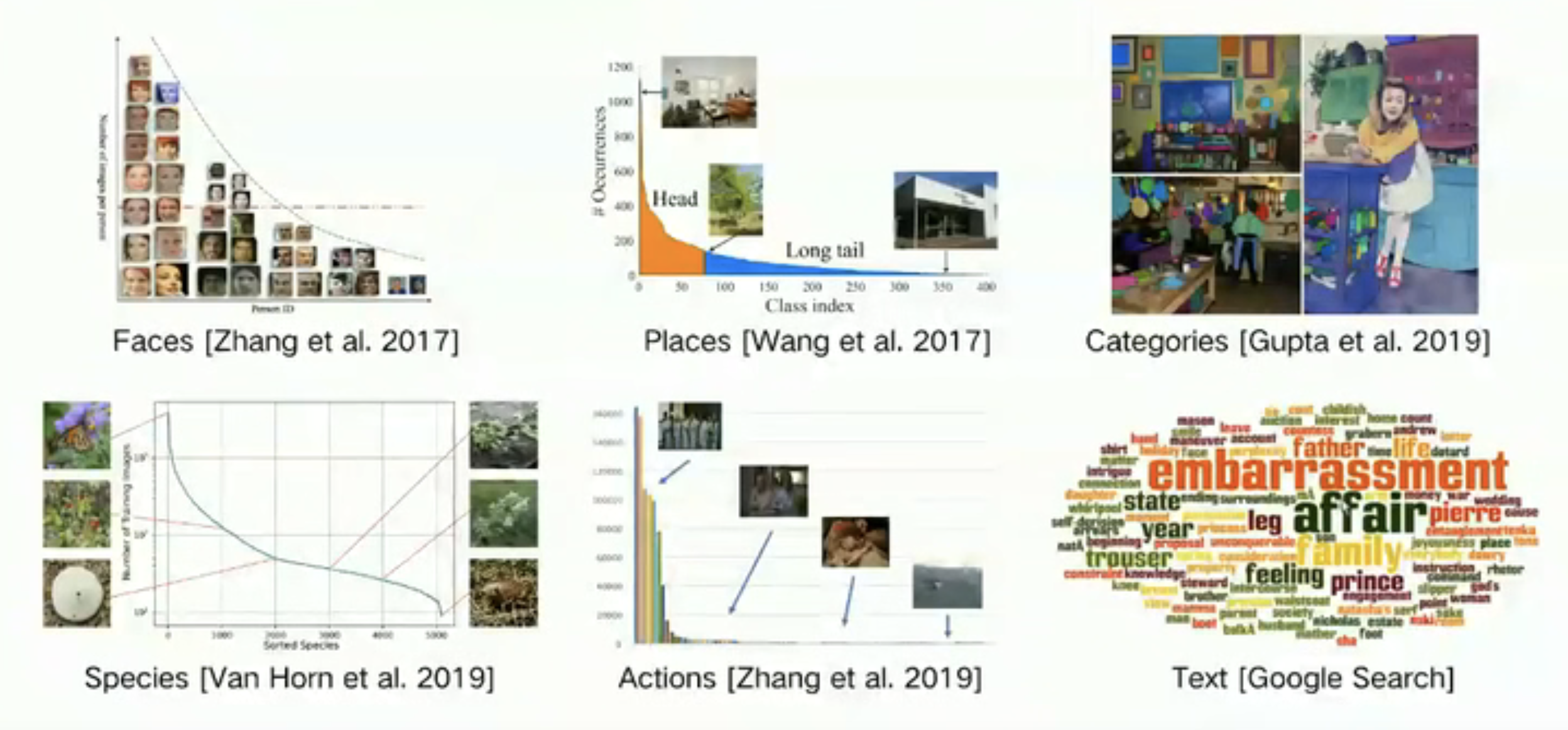
- 类别不平衡是常态
长尾问题
![enter description here]()
长尾问题常见的表现及原因 : - 头部类的效果好,尾部类的效果差
- 模型是数据驱动的,头部类的数据多,尾部类的数据少
- 尾部类数量少的同时可能造成类别中样本差异较大,网络学习不充分
Resampling
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition

论文链接:https://arxiv.org/pdf/1912.02413.pdf
two stage finetuning:
- 第一阶段在原始不平衡的数据集上训练
- 第二阶段以一个很小的学习率使用resampling/reweighting的方法fintune
根据two stage fintuning方法比只使用resampling/reweighting好的原因做了假设
- reblance的方法有效的原因在于提升了分类器的性能
- 会损害网络学习到的特征
为了验证上述假设,将网络拆解成了分类器和特征提取器两部分,分别实验: - 在第一阶段使用交叉熵和resampling/reweighting训练整个网络
- 将第一阶段特征提取器的参数固定,使用交叉熵和resampling/reweighting训练分类器
为了验证上述假设,将网络拆解成了分类器和特征提取器两部分,分别实验:
- 在第一阶段使用交叉熵和resampling/reweighting训练整个网络
- 将第一阶段特征提取器的参数固定,使用交叉熵和resampling/reweighting训练分类器
设计了一个双分支的网络
主要思想是设计了一个two stage finetuning的训练方式
- 第一阶段在原始不平衡的数据集上训练
- 第二阶段以一个很小的学习率使用resampling/reweighting的方法fintune
根据two stage fintuning方法比只使用resampling/reweighting好的原因做了假设
- reblance的方法有效的原因在于提升了分类器的性能
- 会损害网络学习到的特征
为了验证上述假设,将网络拆解成了分类器和特征提取器两部分,分别实验:
- 在第一阶段使用交叉熵和resampling/reweighting训练整个网络
- 将第一阶段特征提取器的参数固定,使用交叉熵和resampling/reweighting训练分类器



总结下BBN思想中的关键点:
- 第一个采样器是一个公平的采样器
- 第二个采样器是一个resample的采样器
- 两个分支共享权重,减少参数量的同时,让第二个分支受益于第一个分支中更好的特征
- 使用一个adaptor的策略,调节两个分支在网络训练中的权重
下面是添加BBN的结果和其他方法的对比:

Cost-sensitive learning
Class-Balanced Loss Based on Effective Number of Samples
论文链接: https://arxiv.org/pdf/1901.05555.pdf
之前方法存在的问题:在reweighting等方法中,一般将样本数量的倒数作为该类别的权重,但是样本之间能提供的信息可能存在重合,简单通过样本数量判断权重会存在问题
- 提出了一种计算有效样本的方法
- 用有效样本数代替原始的样本频率,再用其倒数对损失进行加权

有效样本的定义:
- 样本的有效数据量是样本的期望体积,一个新的采样数据只能存在两种情况
- 新样本存在于之前样本中的概率为p
- 新样本不存在于之前样本中的概率为1-p
提出有效样本的计算公式:
当n=1时,
假设当n=k-1时成立,即,
设样本的体积为K,已经采样的样本体积为。则,经过k次采样后,第k次采样时有以下情况:
- 第k次采样和之前样本存在重叠的情况,则样本体积为
- 第k次采样是新的有效样本,与之前不存在重叠的情况,则样本体积为
期望体积为:
其中
则有效数据量是数据总量n的指数函数,超参数
有效数据量具有如下性质:
- 当n很大时,有效数据量等于n
- 当n为1时,有效数据量为1
CB-Loss:
贴一下实验结果:
Transfer Learning
Feature Space Augmentation for Long-Tailed Data
论文链接:https://arxiv.org/abs/2008.03673
常见的解决方法,如data manipulation和Balanced loss function design在提升长尾数据集模型性能的同时会损害特征表示能力
两个假设:
- 头部类中类别无关的特征可以让尾部类特征更加丰富
- 高级特征空间具有更“线性”的表示,可以提取类通用和类特定的特征,并重新混合生成新的样本
方法:
CAM(Class Activation Map)
c: class; x,y: pixel position; k: channel; w: weight; f: feature,将M归一化到[0,1],设定两个阈值。。则类特定特征和类通用特征分别为:


- 正常训练得到特征提取网络和分类器,使用注意力机制CAM图做特征分解,将特征分为类别无关的特征和类别特定的特征。
- 两阶段训练,第一阶段正常训练,负责提取特征和cam,第二阶段是做尾部类的增广训练,分为两步
- 网络输入一张头部类图片和一张尾部类图片,通过分类置信度排序,选择和当前尾部类距离最近的头部类特征,融合头部类中类通用特征和尾部类中类特征特征

- 使用增强的特征图微调FC分类器层

欢迎关注我的公众号!
