扩散模型汇总——从DDPM到DALLE2
背景知识
扩散模型最早是在2015年在Deep unsupervised learning using nonequilibrium thermodynamics中提出,其目的是消除对训练图像连续应用的高斯噪声,可以将其视为一系列去噪自编码器。它使用了一种被称为“潜在扩散模型”(latent diffusion model; LDM)的变体。训练自动编码器将图像转换为低维潜在空间。随后在2020年提出的DDPM将扩散模型的思想用于图像生成。
生成模型: 给定来自感兴趣分布的观察样本x,生成模型的目标是学习对其真实数据分布$p(x)$进行建模
隐变量(latent Variable): 对于许多模态,我们可以将我们观察到的数据视为由相关的看不见潜在变量生成的,我们可以用随机变量 z 表示。为什么能用看不见的潜在变量表示,感性的理解可以参考柏拉图洞穴的寓言。在这个寓言中,一群人一生都被锁在一个山洞里,只能看到投射在他们面前的墙上的二维阴影,这是由看不见的三维物体在火前经过而产生的。对于这样的人来说,他们所观察到的一切,实际上都是由他们永远看不到的更高维度的抽象概念决定的。
生成模型发展到如今有下图中几种流派,从下面的算法结构图可以看出Diffusion model相比其他方法有比较大的不同:
- Diffusion model的算法过程中的latent Variable维度都是相同的
- 存在一个前向和反向的过程
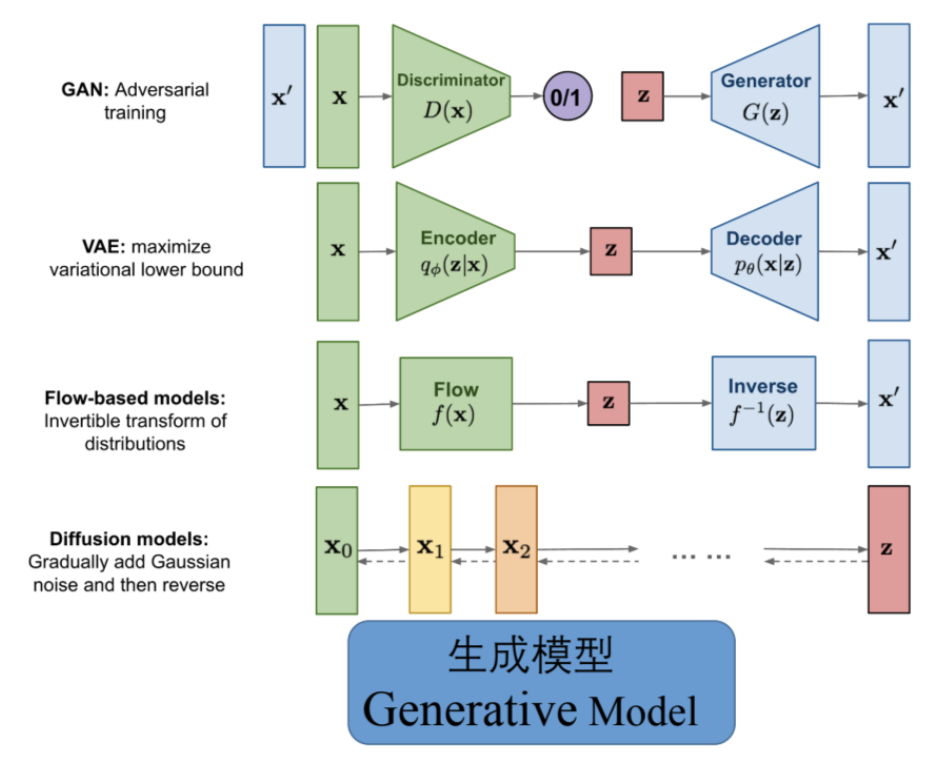
从以上的不同出发,可以推测出Diffusion model包含两个过程:分别是前向过程和反向过程
前向过程
前向过程在论文中也称为扩散过程(diffusion process),是向数据随机添加噪声,直至原始图像整个变成随机噪声的过程,这个过程记为$x_o~q(x_o)$
反向过程
反向过程是前向过程的反转,反向过程的目的是将随机噪声的分布,逐渐去噪生成真实的样本。反向过程实际上也是生成数据的过程。将该过程的表达式为:
DDPM
论文链接: https://arxiv.org/abs/2006.11239
代码链接: https://github.com/hojonathanho/diffusion
在DPM中原始的扩散模型,在反向过程中是用$x_{t-1}$ 预测 $x_{t}$,而DDPM预测的是从t时刻到t-1时刻添加的噪声,只要减去添加的噪声,同样也能得到$x_{t}$时刻的特征。
由于在从噪声恢复到目标图像的过程中,特征维度是一致的,在DDPM中采用的是U-Net的结构,在T步的反向过程中,U-Net模型是参数共享的,为了能告知U-Net模型现在是反向传播的第几步,在每一步反向传播时会增加一个time embedding,其实现和transformer中的position embedding相似
在反向过程中预测的噪声都是符合正态分布的,也就是只用拟合噪声的均值和方差就可以预测出噪声,在DDPM中将方差固定为常数,只预测均值
DDPM的原理到这里基本就介绍完了。关于论文中扩散模型正向和反向过程都是符合高斯分布的,可以做比较详尽的推理和证明,对正向和反向推理过程感兴趣的同学可以看看论文或者其他blog中的推导
improved DDPM
论文链接: https://arxiv.org/abs/2102.09672
代码链接: https://github.com/openai/improved-diffusion
从论文的名字可以看出主要是对DDPM做的改进,主要介绍下和DDPM的差异
- 将DDPM中用常数指代的方差,用模型学习了
- 将添加噪声的schedule改了,从线性的改成了余弦的
作者发现DDPM中线性的噪声schedule在高分辨率的图像生成中表现较好,但对于分辨率比较低的,例如6464和3232的图像任务中表现的不那么好。特别是在扩散过程的后期,最后的几步噪声过大,对样本质量的贡献不大。从Figure 3可以看出,cosine schedule的方法在每一步添加的噪声后相比之前图片都有一些差异,而linear schedule方法,在后期几步差异已经不大了。![]()
我也用coco的数据集试了下,确实cosine比linear要合理些。
下图展示的是前向过程,迭代不同次数的结果


下面以mnist数据集为例,展示反向过程,迭代不同次数的结果

Diffusion models beat GAN on image Synthesis
论文链接: https://arxiv.org/abs/2105.05233
代码链接: https://github.com/openai/guided-diffusion
和之前方法的差异
- 从GAN的实验中得到启发,对扩散模型进行了大量的消融实验,找到了更好的架构更深更宽的模型
- 用了classifier guider diffusion
网络结构消融实验
文中使用的基础模型是U-Net加一个单头全局注意力模块,以FID为评价指标,在ImageNet128128上进行消融实验。
作者从模型的宽度(channels)、深度(depth)、注意力头的数量(heads)、注意力的分辨率(attention resolutions)、*使用BigGAN的上/下采样激活(BigGAN-up/downsample)、调整残差连接的权重(rescale-resblock)等方面进行了消融实验

从上表中可以看到,加宽和加深网络都能带来明显的提升,增加注意力头的数量、使用多分辨率组合的注意力模块比只使用单头单一分辨率更有助于提升模型表现,BigGAN的上下采样也能提升模型表现。唯独修改残差连接的权重没有带来提升。
虽然增加深度能带来模型性能的提升,但也会增加训练时间,并且需要更长时间才能拟合到一个一般结构模型能达到的效果。
另外通过Table 1的实验,作者使用了Channels为128,2个残差块,高分辨率的attention和使用BigGan中的上下采样激活。进一步探究注意力头的数量和每个注意力头通道数间的关系
通过上表的结果进一步证明,注意力头的数量能提升性能,但每个注意力头的通道数并不是越多越好
Classifier Guidance
作者受目前GAN方法里通常会使用的类别信息辅助图像生成的原理启发,开发了一个将类别信息引入扩散模型中的方法Classifier Guidance Diffusion,这个方法通俗的说是会训练一个图片分类器,在扩散模型的生成过程中的中间的latend code会通过分类器计算得到一个梯度,该梯度会指导扩散模型的迭代过程。其实这一操作也比较make sense,有一个分类器的存在能更好的告诉U-Net的模型在反向过程生成新图片的时候,当前图片有多像需要生成的物体。有点类似GAN中存在一个判别器的意思。
在论文中提到使用Classifier Guidance的技术能更好的生成逼真的图像,同时能加速图像生成的速度。论文中也提到,通过使用Classifier Guidance的track会牺牲掉一部分的多样性,换取图片的真实性
Classifier-Free Diffusion Guidance
这篇论文的主要贡献是优化了Openai在《Diffusion models beat GAN on image Synthesis》中提出的Classifier Guidance,在Classifier Guidance中提出用另外一个模型做引导,需要用预训练的模型或者额外训练一个模型。不仅成本比较高而且训练的过程是不可控的。
而这篇论文的方法研究的是没有分类器,也可以用生成模型自己做引导,所以起名叫“Classifier-Free Diffusion Guidance”。具体来说在该方法中联合训练了conditional和unconditional的扩散模型,并且结合了两个模型的score estimates,以实现样本质量和多样性之间的均衡。下图的Algorithms1和Algorithms2详细描述了Classifier-Free的做法。


最终模型的输出为下面的公式:

最终的输出为有条件生成的输出减去无条件生成的输出,看到这里个人感觉和之前介绍的两篇关于因果分析的论文《Unbiased Scene Graph Generation from Biased Training》和《Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect》思路十分相似,可以将无条件生成的输出看作是偏差,用正常训练的网络减去有偏差的网络能得到想要的输出。回到这篇论文的思路,有条件生成的可以看作是用了和图片匹配的文本对c,而无条件生成将其中的文本对c置为了空集。其中w是超参数,用来条件有条件和无条件生成两者的比例,实验部分有该参数对性能的详细对比,以及和其他方法的对比

从下面的结果图可以看出Classifier-Free Guidance相比不用non-guided的方法多样性会有些损失,但图像的真实性和色彩饱和度是要更好的

值得一提的是,虽然Classifier-Free Guidance的方法没有引入新的模型,但方法本身仍然是”昂贵的“,因为训练的时候需要生成两个输出。在扩散模型本身就很慢的情况下,会进一步增加耗时
GLIDE
论文链接: https://arxiv.org/abs/2112.10741
代码链接: https://github.com/openai/glide-text2im
在前面扩散模型的一系列进展之后,尤其是当guidance技术之后证明扩散模型也能生成高质量的图像后。Openai开始探索文本条件下的图像生成,并在这篇论文里对比了两种不同的guidance策略,分别是通过CLIP引导和classifier-free的引导。验证了classifier-free的方式生成的图片更真实,与提示的文本有更好的相关性。并且使用classifier-free的引导的GLIDE模型在35亿参数的情况下优于120亿参数的DALL-E模型
该方法沿袭了Openai一贯的做法,什么模块效果好就用什么,然后进一步增加模型的参数量和数据量。具体而言:
- 使用了更大的模型,其中模型的结构和《Classifier-Free Diffusion Guidance》方法中的模型结构一样,不过增大了通道数,参数量达到了35亿
- 更多的数据,和Dalle相同的图像-文本对
- 更充分的训练,2048的batch size,迭代了250万次
GLIDE最大的贡献是开始用文本作为条件引导图像的生成,下图是其训练过程,和之前工作差异主要有以下几点:
- 分词后将文本送入transformer(bert),生成文本的embedding
- 文本embedding中最后一个token的特征作为扩散模型中classifier-free guidance中的条件c

GLIDE的效果确实十分惊艳,图片非常真实而且有很多细节。
DALLE2
论文链接: https://cdn.openai.com/papers/dall-e-2.pdf
代码链接: https://github.com/lucidrains/DALLE2-pytorch
如果说前面所提到的方法将扩散模型优化到比同期gan模型指标还要好,让研究人员看到了扩散模型在生成领域的前景,那么Dalle2则将扩散模型引入了公众视野。
在GLIDE取得成功之后,Openai又进一步在GLIDE上加了一些track,成为了Dalle2。dalle2的结构如下图所示:

上面的图中将有一条分割线,分割线的上半部分代表CLIP模型,下半部分代表DALLE2。
为了更好的理解DALLE2,回顾一下CLIP模型,CLIP模型是有一个图像-文本对,文本通过一个text encoder得到文本特征,图像通过image encoder得到图像特征。他们两者就是一对正样本,而该文本跟其他的图像就构成负样本。
在Dalle2中CLIP模型没有经过进一步的训练,主要用处是用来根据文本生成文本特征,然后prior根据文本特征生成对应的图像特征,这一步很有意思,在论文中作者认为显式将图像特征建模出来,再用图像特征生成图像,会比直接通过文本特征生成图像效果要好。
方法:
dalle2使用的数据和CLIP,Dalle,GLIDE一样,都是图像文本对(x,y)。x代表图像,y代表图像对应的文本,$z_i$代表CLIP模型输出的图像特征,$z_t$代表CLIP模型输出的文本特征。则Dalle2的网络结构由两部分组成:
- prior: 根据文本y生成图像特征$z_i$
- decoder: 使用prior生成的$z_i$(对应的文本y,y可有可无),生成图像x
作者用公式证明了可以通过两阶段方式生成图像的原因。$P(X|Y)$代表要用文本生成图像,可以等价于$P(x,z_i|y)$,因为可以认为x和图像特征$z_i$是一一对应的,可以根据链式法则等价于$P(z_i|y)$。
Decoder
decoder部分的模型结构和GLIDE基本一致,使用了CLIP模型作为guidance,也使用了classifier-free guidance,并且classifier-free中的guidance有两种,一种是CLIP模型,另外一种是文本。
使用了级联式的生成,即生成的图片先从6464到256256,再到1024*1024
Prior
prior模型的任务是从文本特征生成图像特征,这里有两种常用的方法
- Auto-regressive
- 扩散模型
但是自回归的模型训练效率比较低,所以DALLE2的方法中使用的是扩散模型。在prior模型里也是用到了classifier-free guidance。在模型实现上使用的是transformer的decoder,模型的输入非常多,包含文本、CLIP的text embedding、扩散模型中常见的time step的embedding,还有加过噪声之后CLIP的image embedding;输出则预测没有噪声的CLIP的image embedding。和之前扩散模型不一样的地方在于没有使用DDPM中预测噪声的方式,而是直接还原每一步的图像
最后再贴一贴惊艳的效果
笔者总结
上面总结了各种各样的扩散模型,总体来说扩散模型的可解释性比GAN要好很多,也有很多数学公式可以证明。发展到如今,扩散模型慢慢的接替了GAN在生成领域头把交椅的地位。并且随着Dalle2的提出确实带来了无穷的想象力。在人工智能没有普及的年代,就有讨论随着人工智能的发展有哪些职业会被取代,但是基本上大家都觉得创造性的工作,是无法被取代的,因为创造性的工作没有固定的模式,大多数需要灵感。但目前来看扩散模型已经具有了一定的创造性,相信对大部分的认知都是有一定的冲击,也说明扩散模型确实是一个很有趣的研究方向。
欢迎关注我的公众号!
