一篇文章搞懂iBOT
本文首发于公众号“CVTALK”。
论文链接:https://arxiv.org/abs/2111.07832
代码链接:https://github.com/bytedance/ibot
iBOT完整的名字是IMAGE BERT PRE-TRAINING WITH ONLINE TOKENIZER, 和BEIT: BERT Pre-Training of Image Transformers的名字很相似,iBOT确实受启发于BEIT,另外还使用到了对比学习之前的SOTA——DINO。可以看作是BEIT和DINO的结合,既然和另外两篇文章关系这么大,正好笔者之前也没有写过BEIT和DINO的文章,在介绍iBOT的时候会尽量把BEIT和DINO也给尽量详细的总结出来。
背景知识
BEIT
论文链接: https://arxiv.org/abs/2106.08254
代码链接:https://github.com/microsoft/unilm/tree/master/beit
BEIT这篇论文的标题是BEIT: BERT Pre-Training of Image Transformers,从标题可以看出BEIT受启发于之前在文本领域大火的BERT模型,使用Transformer在图像场景中使用类似BERT中完形填空的方式做预训练。BEIT的名字来源于 Bidirectional Encoder representation from Image Transformers, 即图像transformer的双向编码器。
既然BEIT的思路受启发于Bert,Bert可以说是非常耳熟能详了,为了更好的理解BEIT算法,在回顾的时候,笔者也尽量按照类比Bert中的做法说明BEIT在图像领域中应用的差异。
在Bert或者说NLP中,一般前两步都是Tokenization和Numeralization:
- Tokenization: 分词化,目的是将输入文本划分成一个个小的单元,保证每个单元拥有相对完整和独立的语义。根据划分粒度的差异可以分为字、字词(subword)、词三种粒度。
- Numeralization: 数字化,经过了分词后,为了方便后续的算法处理,需要将词转化为数字。做法是构造一个词表-索引对应的字典,将分词后的数据转化为数字。
在BEIT中,也有类似的操作,叫做image patch和visual token:
- image patch: 和VIT中一样,将HW的图像划分成P P个小的单元,每个单元的大小为$N=HW/P^2$。比较经典的划分方式是将224 224的图片,划分patch数量为16 16,则每个单元格大小为14 * 14
- visual token: NLP中的分词得到的单元是可以穷举的,而在图像中,每一个patch的信息不能直接像NLP中根据分词的结果构建索引。这里使用了discrete vaiational autoencoder(dVAE)。BEIT中并没有训练dVAE模型,而是直接使用的DALLE中训练好的。 dVAE的思想仿照了词汇表,构建了一个特征向量表,称为visual codebook,大小是8192,代表着存储了8192个特征向量。使用的方法是经过image patch后的图片经过encoder得到feature map,用这个feature map和codebook中的特征向量比对,选取codebook中最相似的特征向量作为后续使用的特征向量,而这个特征向量也会对应一串数字。 这样就可以完成图片特征的向量化
在图像中使用visual token有两个好处。第一个显而易见从feature map转换为对应的数字可以节省计算空间,第二个是区别于MAE的方法,MAE中从像素还原图片,会促使模型学习到非常细节的高频特征,而BEIT从visual token还原出图像,迫使模型学习低频的特征,模型可能具有更好的分类能力。
Bert中的预训练任务是将token mask掉,用其他没有mask掉的token预测被mask掉的部分,完成完形填空。回到BEIT中也是类似的思路,将image patch转换为visual token之后,也可以通过mask掉部分image patch,通过其他的image patch预测出被mask掉的部分,完成图像的’完形填空’。
BEIT的结构如下图所示:

图中上半部分是dVAE的训练流程,再强调下,BEIT中没有训练dVAE,因此decoder复原图像的部分在BEIT的流程中实际是不存在的;其余的部分就是和image transformer的部分。dVAE和image transformer一样对整张图划分为44的网络,通过dVAE会得到每个patch的visual token,image transformer中的训练目标是预测被mask掉部分的visual token。图中
*Masked Image Modeling Head是一个softmax分类器,目标是被mask掉部分经过transformer后的embedding和分类出的类别和visual token是一致的。
DINO
论文链接:https://arxiv.org/abs/2104.14294
代码链接:https://github.com/facebookresearch/dino
DINO是一篇用对比学习做自监督的文章,模型的结构和BYOL相似。网络的架构如下:

DINO名字的来源是self-distillation with no labels, 没有标签数据的自蒸馏,原因是采用自监督学习的方式,并且自己跟自己学习。既然是蒸馏的任务,那就需要student和teacher了,DINO将MOCO中的encoder和momentum encoder分别改成了student和teacher的命名方式。
DINO的伪代码如下图所示:

DINO继承了其他对比学习的方法中伪代码清晰易懂的优良传统,既然DINO和BYOL相似,可以看作是BYOL的改进工作,下面在介绍DINO伪代码的同时,将其与BYOL的差异一并阐述:
- 初始化teacher和student网络,teacher网络的参数和student一致。student网络结构和BYOL基本一致,区别在于backbone部分使用了VIT,并且没有使用projection head和prediction head作为限制模型坍塌的结构
- 一个batch的图片x, 经过两种不同的增广分别得到x1, x2;
- x1和x2分别经过student网络和teacher网络,得到s1,s2,t1,t2;
- 算loss的时候平均s1&s2和t1&t2的交叉熵loss,值得注意的是在交叉熵损失里,加入了centering和sharpening避免模型坍塌。DINO的作者认为这是比BN和添加projection head&prediction head更好的方式。下面具体介绍下:
- centering是将一个batch中的样本特征算一个均值, 计算loss时样本的特征需要减去该均值,centering实际上的作用和BN比较相似
- sharpening是将centering之后的特征除以特定的值
tpt做为最后计算交叉熵的特征 - 具体代码为:
t = softmax((t - C) / tpt, dim=1)
- 梯度反传并更新student网络
- 与BYOL和MOCO一样,采用动量更新的方式,更新teacher网络的参数
- 采用动量的方式,更新
center的参数。
IBOT
介绍完了DINO和BEIT之后,终于要迎来主角iBOT了。这里引用iBOT论文中的原话总结iBOT:
self-distillation as a token-generation self-supervised objective
即结合了自蒸馏和重建visual token的自监督算法。
iBOT的网络结构图如下图所示:
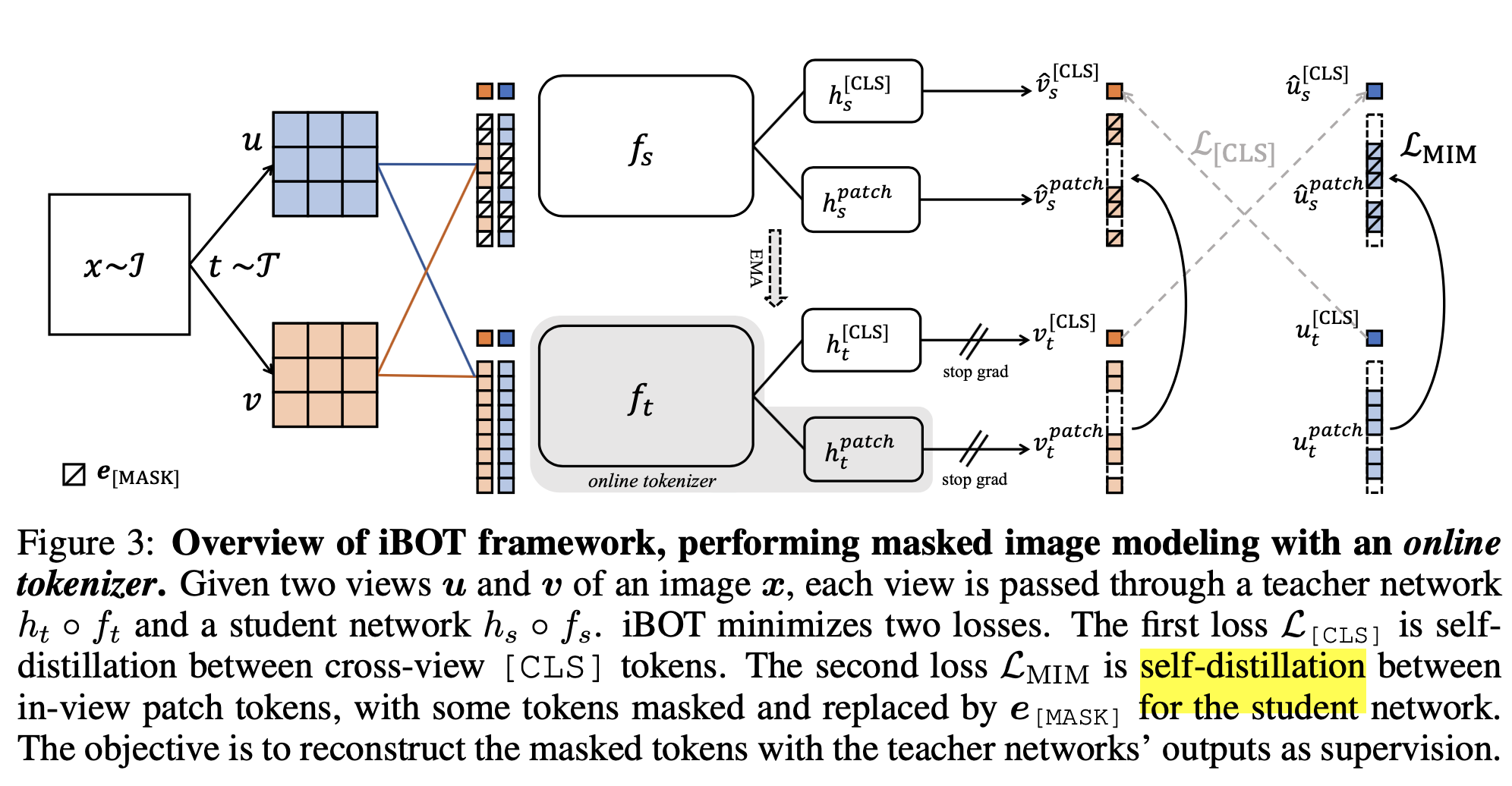
在前面的方法一样,为了加深理解,在介绍iBOT方法的时候,将其与DINO和BEIT做对比:
- 和DINO一样,一个batch的图像x,经过两种不同的增广方式得到$\mu$和$\nu$
- 和DINO一样,$\mu$和$\nu$分别要胫骨student和teacher两个网络,不一样的是student中的图片要和BEIT中一样mask掉一部分
- student和teacher网络的输出会有两部分,一部分是和DINO中类似的$h_{s}^{[CLS]}$,另一部分是和BEIT中类似的$h_{t}^{patch}$
- 训练的目标有两部分,一部分是和DINO类似,student的$\mu$和$\nu$经过image path,mask之后输出$\hat{\mu}_{s}^{[CLS]}$和$\hat{\nu}_{s}^{[CLS]}$, teacher类似输出$\mu_{s}^{[CLS]}$和$\nu_{s}^{[CLS]}$, 平均$\hat{\mu}_{s}^{[CLS]}$&$\mu_{s}^{[CLS]}$和$\hat{\nu}_{s}^{[CLS]}$&$\nu_{s}^{[CLS]}$的交叉熵损失。第二部分和BEIT类似,student的$\mu$和$\nu$经过image path,mask之后输出被mask的patch的特征$\hat{\mu}_{s}^{patch}$和$\hat{\nu}_{s}^{patch}$,teacher类似,和student对应的patch输出为$\mu_{s}^{patch}$和$\nu_{s}^{patch}$, 期望是student得到的visual token和teacher没有被mask部分的visual token一致。两部分loss的公式如下:
- 和DINO中一样, teacher网络的参数通过student的参数做动量更新
- 和BEIT中不一样的是iBOT强调了MIM的学习,dVAE的部分也是参与训练的。论文题目中也特地提到了online tokenizer。


实验
分类
iBOT也算是对比学习的一种方法,因此比较重要的指标就是能否提取到比较好的图片表征,下面是和其他方法在imageNet分类任务上的对比,iBOT是优于DINO和其他方法的。

KNN&linear prob
下面是用KNN和linear probing的imageNet上能取得的效果。KNN的实验是将网络backbone的特征冻结,模型的输出训练KNN进行分类;linear probing也是将backbone的特征冻结,加一个linear prob层,只训练linear prob完成分类。
finetune
fintune的效果,可以看做是用所有的数据finetune整个网络
Semi-supervised Learning
增加一个linear prob层用于分类,只使用1%或者10%的数据训练网络的backbone和linear prob分类器。

下游任务
看完了分类后,下面是在其他的下游任务上的效果
目标检测和分割任务

迁移学习

MIM学习到模式的可视化
和dVAE一样,展示了一些MIM所学习到的东西,作者发现iBOT对于局部语义有非常好的可视化效果,下图左边两张是车灯和狗的耳朵,聚类出的图片也基本属于这两个类别;右边两张展示的则是局部的纹理,聚类出的图片也是非常相似的。
总结
之前介绍的SAM中使用的image encoder是MAE,因为MAE能复原图像,表明MAE学习到了比较好的图像表征。对比学习的训练方式也能让模型学习到很好的图像表征,在DINO和在iBOT基础上优化的DINO2对特征做的可视化图片都能表明,对比学习的任务学出来的特征甚至比一些专门做分割训练的模型,具有更好的特征。iBOT将MIM和Contrastive Learning两种思想结合起来还是非常有意思的,而且论文中提到,student和teacher网络中MIM和Contrastive Learning的MLP层共享参数,能获得更好的效果,说明两个任务结合在一起是可以互相促进的。也许这也是图片领域foundation model的一种实现路径!
