《Mask TextSpotter》论文笔记
论文链接:https://arxiv.org/abs/1807.02242
代码链接:https://github.com/lvpengyuan/masktextspotter.caffe2
除了自然场景的目标检测外,文本检测也是近年来热门的研究领域。Mask TextSpotter是ECCV 2018发表的一篇文本检测文章,具有以下特点:
- 端到端的检测+识别框架
- 基于Mask R-CNN结构
- 在处理不规则的文本形状时,优于之前的方法
- 除了文本行检测外,能进行字符分割
Mask R-CNN结构是近几年来最优秀的目标检测结构了,该篇文章将其应用到文本检测这一任务上,并且所做的优化算是十分巧妙了。
介绍
Mask TextSpotter提出了一种名为掩码文本检测的文本检测器,它可以检测和识别任意形状的文本。

上图直观的比较了不同的检测方法其场景文本定位的效果,左图是水平水平文本定位方法,中间是支持倾斜框的文本检测方法,右图是Mask TextSpotter的检测方法。
可以看到Mask TextSpotter相比较于其他两种方法能够提供更准确的定位图,为后续的识别提供良好的检测效果。
这篇文章总共有四点贡献:
- 提出了一种端到端的文本检测加识别模型,具有简单高效的特点
- 该方法可以检测和识别各种形状的文本,包括水平文本、定向文本和弯曲文本
- 与之前的方法相比,该方法通过语义分割来实现精确的文本检测和识别
- 在各种基准的文本检测和定位上都达到了state-of-the-art的效果
相关工作
这部分主要介绍了场景文本检测、识别及结合的发展进程。强调了Mask TextSpotter基于Mask R-CNN,区别在于该方法不仅可以分割文本,也可以进行字符分割。
方法
框架
Mask TextSpotter的架构如下图所示:
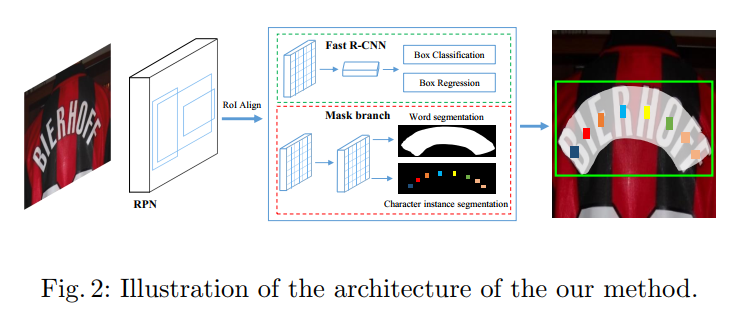
该架构由以下4部分组成
- backbone:ResNet50;FPN网络( top-down 结构)
- 生成文本建议:RPN
- 边界框回归:Fast R-CNN
- 文本和字符实例分割:mask branch
首先由RPN生成大量的文本提案,然后将提案的RoI特征输入Fast R-CNN分支和mask分支中,生成准确的文本候选框、文本实例分割图和字符分割图。
每部分的细节如下:
- Backbone:自然场景的文本大小不一,为了提取更高层的语义特征。采用了ResNet-50网络,并用对小目标有较好效果的FPN网络提取特征
- RPN:RPN网络为Fast R-CNN分支以及mask分支生成文本建议。anchor设置5种尺寸$\{32^2,64^2,128^2,256^2,512^2\}$,FPN网络中有5个层级$\{P_2,P_3,P_4,P_5\}$,3种比例$\{0.5,1,2\}$。区域特征映射方式采用ROI Align。
- Fast R-CNN:包括分类和回归任务,主要作用是为了后续的检测提供更精确的检测框。
- Mask 分支:掩码分支有两个任务,分别是全局文本实例分割和字符分割。如下图所示。Mask分支的输入是固定大小的ROI(1664),经过4个卷积层和一个反卷积层将特征图降维到38个维度(特征图大小:32128)。这38个维度由以下3部分组成:
- 全局文本实例分割
- 背景分割
- 10个数字,26个字母

标签的生成
为了满足训练的要求,ground truth要包含$P=P\{p_1,p_2…p_m\}$以及$C=\{c_1=(cc_1,cl_1),c_2=(cc_2,cl_2),…,c_n=(cc_n,cl_n)\}$。其中$p_i$表示一个文本定位的多边形。$cc_j$和$cl_j$分别是字符的类别和定位。值得一提的是并不要求所有样本都需要有标记$C$。
首先用涵盖目标最小水平矩形面积的方法,将多边形转换为水平矩形。然后通过RPN和Fast R-CNN网络生成区域建议。对于具有ground truth P, C(可能不存在)的mask分支,需要生成两种类型的目标映射,以及RPN生成的建议:用于全局实例分割的映射和用于字符实例分割的映射。对于正样本的proposal,首先得到最匹配的水平矩形。相应的多边形及字符(如果有的话)可以进一步得到。在映射$H×W$上调整多边形和字符的proposal一致的公式如下:

其中$(B_{x0},B_{y0})$是所有多边形和字符原始的顶点,$(B_x,B_y)$是所有多变形和字符更新后的顶点,$(r_x,r_y)$是rpoposal产生的顶点。
然后,全局映射图的生成规则:通过绘制zero-initialized mask的规则多边形;字符边界框的生成:固定所有字符的中心点,并将边缩短到原始边的1/4。如下图所示:

损失函数
该部分讨论的是整个框架优化参数时的损失函数组成,正如上面介绍的Mask TextSpotter的框架由4部分组成,除了提取特征的网络外,其余的3部分都是损失函数的组成部分,如下所示:

mask分支有两个任务,因此$L_{mask}$的计算如下:

其中$L_{global}$为Cross entropy损失,而$L_{char}$为Softmax损失。其中作者设置的超参数$α_1,α_2,β$都为1。
$L_{global}$的计算公式如下:

$L_{char}$的计算公式如下:

其中T为类别,X为预测的输出,Y为gt,W为权重。W的主要作用是为了样本均衡。不同类别的W计算公式如下:

推理(测试)
不同于mask 分支的ROI来自于RPN网络,在推理阶段,mask分支的ROI来自于Fast R-CNN网络,而不是RPN网络,这是由于Fast R-CNN的输出更精确。
推理阶段可以分为以下几个过程:
- 输入测试图片,获得Fast R-CNN的输出,并经过NMS;
- 保存下来的proposals被输入mask分支以生成全局映射(gloabal maps)和字符映射(character maps)
通过计算全局映射的map区域获得预测的多边形,通过pixel voting算法生成字符映射序列
pixel voting算法的细节如下:
- 二值化背景图,阈值为192
- 根据二值化中的联通与划分所有字符区域
实验
作者总共使用了4个数据集,除了SynthText用来预训练以外,其余的三个数据集ICDAR 2013,ICDAR2015,Total_Text均做了测试实验。






通过以上实验数据比较,Mask TextSpotter水平文本、定向文本和弯曲文本等数据集上的良好性能证明了该方法对文本检测和端到端文本识别的有效性和鲁棒性。
欢迎关注我的公众号
