《Receptive Field Block Net for Accurate and Fast Object Detection》论文笔记
论文链接:https://arxiv.org/abs/1711.07767
论文代码:https://github.com/ruinmessi/RFBNet
这篇文章是CV领域顶会ECCV2018中关于目标检测的文章,文中以SSD模型为基础提出了RFB结构,强调兼顾速度与性能。说来也巧,因为项目需要,在看这篇论文之前正好看过提出dilated convolution的那篇文章,但是dilated convolution的结构获得更大感受野的方式确实对细粒度的分割会比较好,适用图像分割领域。当我还在想能怎么用在目标检测上时,就看到了RFB网络。虽然作者说是为了兼顾速度与性能将其应用到one stage的SSD上,但我也在two stage的faster rcnn上,复现出了较好的效果。这是一篇我个人很喜欢的文章,实验充分,模拟视觉细胞的结构让我觉得即简单又巧妙。因此简单总结下这篇文章。
绪论
作者指出目前图像领域深度学习的发展越来越倾向于用更深的网络以达到更好的效果,然而像ResNet等很深的网络往往具有较大的计算量,导致速度受限。相比之下作者提出的RFB结构具有以下优点:
- 模拟了人类视觉系统RFs的大小和离心率设置,增强轻量级CNN网络的特征提取能力
- 简单的替换了SSD的最后一级卷积层,在较少的计算增加的情况下,提升了模型的性能
- 除了SSD之外,也扩展到了MobileNet中取得了较好的结果,展示了结构的泛化性
相关工作
这部分就不总结了,主要介绍了one stage和two stage的目标检测模型和目前论文中在感受野上做的研究。
方法
视觉皮层

如上图所示是人类感受野(pRF)的示意图,可以看到有以下规律:
- 距离中心越远的pRF越大,即pRF大小与偏心含有正相关的关系
- 不同图谱的pRF大小规模不同
感受野块


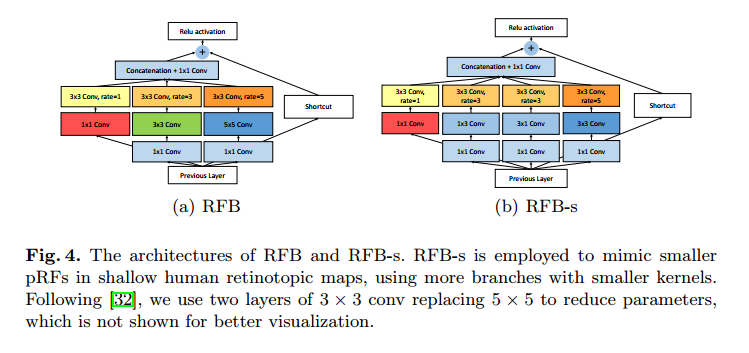
作者提出的RFB结构的原理如上图所示,该结构的特点有:
- 多分支卷积层:根据之前人类感受野(pRF)的示意图,为了仿照不同图谱的pRF大小规模不同,作者提出用不同大小的卷积核以实现多大小的pRF,这一方法应该优于共享固定大小的RFs。这一结构参考了Inception的结构。
- 膨胀卷积和池化层:膨胀卷积的基本意图在于生成分辨率更高的特征图,在相同计算量的情况下获得更大的感受野。而膨胀卷积核的大小和扩张与pRFs在视觉皮层的大小和偏心具有相似的功能关系。然后再将不同膨胀卷积处理过的层融合起来,以达到视觉皮层中感受野的效果。rFB的结构如下图所示:
RFB检测框架
作者提出的RFB的结构是在SSD的基础上改的,做的修改及替换如下图所示:

- 轻量级的结构:这里主要说的是SSD的有点,这里不赘述
- 多尺度结构中的RFB:在原始的SSD中,有着层叠的卷积层,形成一系列空间分辨率连续下降、感受野不断增大的feature map。在作者的实现中,保持了相同的SSD级联结构,但具有较大感受也的卷积层被RFB结构替代。作者还指出最后基层卷积层的特征图太小,适合用5X5大小的卷积核。这部分论文里Fig.4的a图中用的确实是5x5的卷积核,但是给出的代码中却用两个3x3的卷积核替代了,这部分我有点疑惑。
实验
这一部分就是各种各样的实验图表了,也不赘述。从以下图表可以看到实验结果确实很惊艳,用了RFB结构的网络mAP会有不小的提升。




作者还给出了一张目前目标检测算法的准确率和耗时的图片,对比的多是one stage的模型,可以作为参考
欢迎关注我的公众号
